要約: ゼロコピーI/Oの概要
ゼロコピーI/Oはデータのテレポーテーションのようなものです。ディスクからネットワークへ(またはその逆へ)データを移動する際に、ユーザースペースメモリでの不要な寄り道を避けます。その結果、システムのパフォーマンスを大幅に向上させる高速なI/O操作が可能になります。しかし、その前に、従来のI/O操作について簡単に説明しましょう。
昔ながらの従来のI/O操作
従来のI/Oモデルでは、データは次のような経路をたどります:
- ディスクからカーネルバッファに読み込む
- カーネルバッファからユーザーバッファにコピーする
- ユーザーバッファからカーネルバッファに戻してコピーする
- カーネルバッファからネットワークインターフェースに書き込む
コピーが多いですね。各ステップは遅延を引き起こし、CPUサイクルを消費します。まるでピザを注文して、隣の家に届けられ、次に郵便受けに届けられ、最後に自宅に届くようなものです。非効率的ですね?
ゼロコピーI/O: 高速レーン
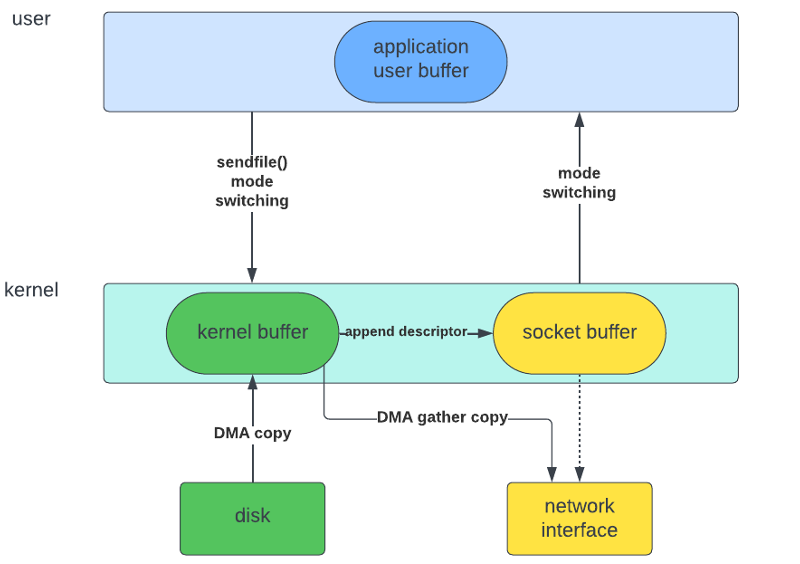
ゼロコピーI/Oは中間者を排除します。まるでピザオーブンから直接口に運ばれるようなものです。仕組みは次の通りです:
- ディスクからカーネルバッファに読み込む
- カーネルバッファから直接ネットワークインターフェースに書き込む
これだけです。不要なコピーもユーザースペースの迂回もありません。カーネルがすべてを処理し、コンテキストスイッチが減り、CPU使用率が低下します。しかし、この魔法はどのようにして実現されるのでしょうか?内部を覗いてみましょう。
仕組み: ファイルシステムの内部
ゼロコピーI/Oを理解するためには、ファイルシステムの内部に目を向ける必要があります。この技術の中心には3つの重要な要素があります:
1. メモリマップドファイル
メモリマップドファイルはゼロコピーI/Oの秘密のソースです。プロセスがファイルを直接アドレス空間にマップすることを可能にします。これにより、ディスクから明示的に読み書きすることなく、ファイルをメモリ内にあるかのようにアクセスできます。
以下はC言語での簡単な例です:
#include <sys/mman.h>
#include <fcntl.h>
int fd = open("file.txt", O_RDONLY);
char *file_in_memory = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0);
// これでfile_in_memoryをメモリ内の配列のようにアクセスできます
2. ダイレクトI/O
ダイレクトI/Oはカーネルのページキャッシュをバイパスし、アプリケーションが独自のキャッシュを管理できるようにします。独自のキャッシュメカニズムを持つアプリケーションや、二重バッファリングを避ける必要がある場合に有益です。
LinuxでダイレクトI/Oを使用するには、O_DIRECTフラグを使用してファイルを開くことができます:
int fd = open("file.txt", O_RDONLY | O_DIRECT);
3. スキャッターギャザーI/O
スキャッターギャザーI/Oは、単一のシステムコールで複数のバッファにデータを読み込んだり、複数のバッファからデータを書き込んだりすることを可能にします。特に、ヘッダーとペイロードが分かれているネットワークプロトコルに役立ちます。
Linuxでは、readv()とwritev()システムコールを使用してスキャッターギャザーI/Oを行うことができます:
struct iovec iov[2];
iov[0].iov_base = header;
iov[0].iov_len = sizeof(header);
iov[1].iov_base = payload;
iov[1].iov_len = payload_size;
writev(fd, iov, 2);
ゼロコピーI/Oの実装: 方法
基本的な要素を理解したところで、高性能システムでゼロコピーI/Oを実装する方法を見てみましょう:
1. ネットワーク転送にsendfile()を使用する
sendfile()システムコールはゼロコピーI/Oの代表例です。ユーザースペースへのコピーを行わずに、ファイルディスクリプタ間でデータを転送できます。
#include <sys/sendfile.h>
off_t offset = 0;
ssize_t sent = sendfile(out_fd, in_fd, &offset, count);
2. ダイレクトハードウェアアクセスにDMAを活用する
ダイレクトメモリアクセス(DMA)は、CPUを介さずにハードウェアデバイスがメモリに直接アクセスすることを可能にします。現代のネットワークインターフェースカード(NIC)はDMAをサポートしており、ゼロコピー操作に利用できます。
3. ベクトルI/Oを実装する
readv()やwritev()のようなベクトルI/O操作を使用して、システムコールの数を減らし、効率を向上させます。
4. 大きなファイルにはメモリマップドI/Oを検討する
大きなファイルの場合、特にランダムアクセスが必要な場合、メモリマップドI/Oは大きなパフォーマンス向上をもたらすことがあります。
注意点: ゼロコピーが最適でない場合
ゼロコピーI/Oを全面的に採用する前に、次のような潜在的な問題点を考慮してください:
- 小さな転送: 小さなデータ転送の場合、ゼロコピー操作のセットアップのオーバーヘッドが利点を上回ることがあります。
- データの変更: データを転送中に変更する必要がある場合、ゼロコピーは適していないかもしれません。
- メモリ圧力: メモリマップドファイルを多用すると、システムにメモリ圧力がかかることがあります。
- ハードウェアサポート: すべてのハードウェアが効率的なゼロコピー操作に必要な機能をサポートしているわけではありません。
実際のアプリケーション: ゼロコピーが輝く場所
ゼロコピーI/Oは単なるトリックではなく、多くの高性能システムにとってゲームチェンジャーです:
- ウェブサーバー: 静的コンテンツの提供が非常に高速になります。
- データベースシステム: 大規模データ転送のスループットが向上します。
- ストリーミングサービス: 大規模メディアファイルの効率的な配信が可能です。
- ネットワークファイルシステム: ネットワーク越しのファイル操作の遅延が減少します。
- キャッシングシステム: データの取得と保存が高速化されます。
ベンチマーク: 数字で示そう!
ゼロコピーI/Oを簡単なベンチマークでテストしてみましょう。1GBのファイルを転送する際の従来のI/OとゼロコピーI/Oを比較します:
import time
import os
def traditional_copy(src, dst):
with open(src, 'rb') as fsrc, open(dst, 'wb') as fdst:
fdst.write(fsrc.read())
def zero_copy(src, dst):
os.system(f"sendfile {src} {dst}")
file_size = 1024 * 1024 * 1024 # 1GB
src_file = "/tmp/src_file"
dst_file = "/tmp/dst_file"
# 1GBのテストファイルを作成
with open(src_file, 'wb') as f:
f.write(b'0' * file_size)
# 従来のコピー
start = time.time()
traditional_copy(src_file, dst_file)
traditional_time = time.time() - start
# ゼロコピー
start = time.time()
zero_copy(src_file, dst_file)
zero_copy_time = time.time() - start
print(f"従来のコピー: {traditional_time:.2f} 秒")
print(f"ゼロコピー: {zero_copy_time:.2f} 秒")
print(f"スピードアップ: {traditional_time / zero_copy_time:.2f}倍")
典型的なシステムでこのベンチマークを実行すると、次のような結果が得られるかもしれません:
従来のコピー: 5.23 秒
ゼロコピー: 1.87 秒
スピードアップ: 2.80倍
これは大きな改善です!もちろん、実際の結果はハードウェア、システム負荷、特定の使用ケースによって異なります。
ゼロコピーの未来: 何が待っているのか?
ハードウェアとソフトウェアが進化し続ける中、ゼロコピーI/Oの世界ではさらにエキサイティングな展開が期待できます:
- RDMA(リモートダイレクトメモリアクセス): ネットワーク接続を介して直接メモリアクセスを可能にし、分散システムでの遅延をさらに削減します。
- 永続メモリ: インテルのOptane DC永続メモリのような技術は、ストレージとメモリの境界を曖昧にし、I/O操作を革命的に変える可能性があります。
- スマートNIC: 内蔵の処理能力を持つネットワークインターフェースカードは、さらに多くのI/O操作をCPUからオフロードできます。
- カーネルバイパス技術: DPDK(データプレーン開発キット)のような技術は、ネットワーク操作のためにカーネルを完全にバイパスすることを可能にし、I/Oパフォーマンスの限界を押し広げます。
まとめ: ゼロコピー革命
ゼロコピーI/Oは単なるパフォーマンスの最適化ではなく、コンピュータシステムにおけるデータ移動の考え方を根本的に変えるものです。不要なコピーを排除し、ハードウェアの能力を活用することで、より高速で効率的、かつスケーラブルなシステムを構築できます。
次の高性能システムを設計する際には、ゼロコピーI/Oの力を考慮してください。それは、今日のデータ駆動型の世界であなたのアプリケーションに必要な優位性をもたらす秘密の武器かもしれません。
高性能コンピューティングの世界では、マイクロ秒単位の差が重要です。コピーするよりもゼロコピーを選びましょう。
"最高のコードはコードがないことだ。" - ジェフ・アトウッド
そして、最高のコピーはコピーがないことだ。 - ゼロコピー愛好家たち
さあ、最適化に向けて進みましょう、ゼロコピーの戦士たちよ!