無限の空間の幻想
仮想メモリの本質は、存在しないメモリを持っているかのような幻想を作り出すことです。しかし、この魔法のような仕組みはどのように機能しているのでしょうか?
ページテーブルの登場
ページテーブルは、メモリ管理の無名のヒーローです。仮想アドレスの広大な空間と物理メモリの限られた領域をつなぐ地図のような役割を果たします。以下はその仕組みの簡単な説明です:
struct PageTableEntry {
uint32_t physical_page_number : 20;
uint32_t present : 1;
uint32_t writable : 1;
uint32_t user_accessible : 1;
uint32_t write_through : 1;
uint32_t cache_disabled : 1;
uint32_t accessed : 1;
uint32_t dirty : 1;
uint32_t reserved : 5;
};
ページテーブルの各エントリは、通常4KBの仮想メモリのページに対応しています。プログラムがメモリにアクセスしようとすると、CPUはページテーブルを使ってそのメモリが実際に物理RAMのどこにあるかを確認します。
翻訳のコスト
しかし、ここに問題があります。ページテーブルを通じてアドレスを翻訳するのは遅いのです。本当に遅いです。まるでペンキが乾くのを見ているような遅さです。メモリアクセスごとに、CPUは実際のデータがどこにあるかを確認するために複数のメモリルックアップを行う必要があります。ここで次のプレイヤーが登場します...
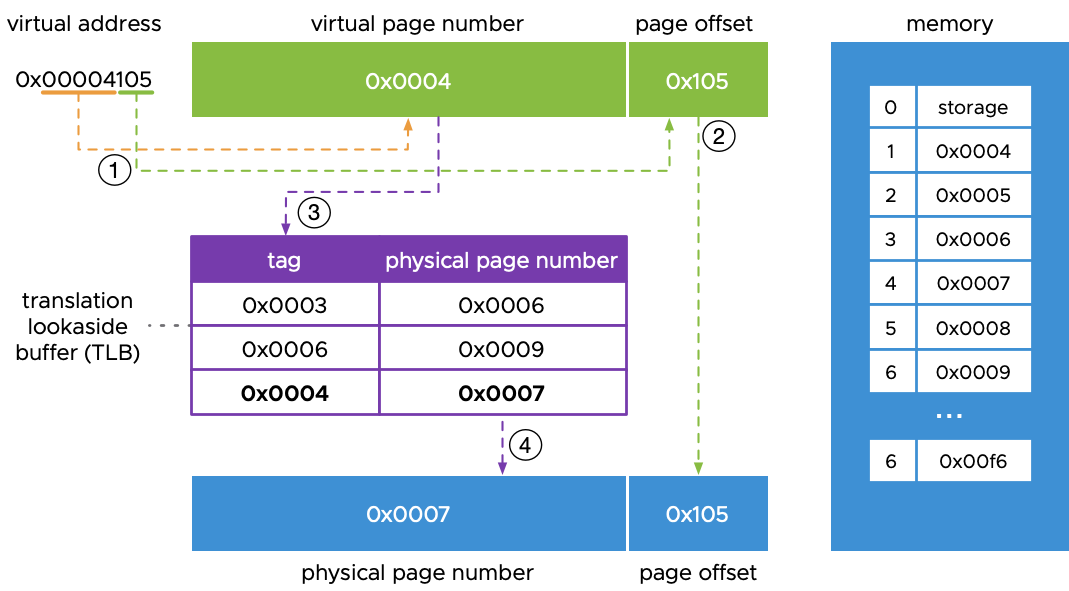
TLB: アドレス翻訳のスピードデーモン
トランスレーション・ルックアサイド・バッファ(TLB)は、仮想メモリエンジンのニトロのようなものです。仮想アドレスから物理アドレスへの最近の翻訳を保存する小さくて高速なキャッシュです。
TLBを、道順を覚えるための短期記憶のように考えてください。毎回地図(ページテーブル)を取り出す代わりに、最近行った場所ならルートを覚えているのです。
TLBの魔法の仕組み
TLBがどのように動作するかの簡単な擬似コードです:
def access_memory(virtual_address):
if virtual_address in TLB:
physical_address = TLB[virtual_address]
return fetch_data(physical_address)
else:
physical_address = page_table_lookup(virtual_address)
TLB[virtual_address] = physical_address
return fetch_data(physical_address)
このシンプルな仕組みはメモリアクセスを劇的に高速化します。実際、現代のCPUはTLBのヒット率が99%以上になることもあり、100回のメモリアクセスのうち99回は遅いページテーブルに触れる必要がありません。
暗黒面: TLBミスとスラッシング
しかし、TLBが翻訳を見つけられないとどうなるでしょうか?これはTLBミスと呼ばれ、金曜日の午後4時59分に本番コードでバグを見つけるようなものです。
TLBミスが発生すると、CPUは次のことを行う必要があります:
- 正しい翻訳を見つけるためにページテーブルを歩く
- 新しい翻訳でTLBを更新する
- メモリアクセスを再試行する
このプロセスは非常に遅く、頻繁に発生するとパフォーマンスが急激に低下します。この状態はTLBスラッシングと呼ばれ、パフォーマンスに敏感なアプリケーションにとって悪夢のようなものです。
スラッシングを避ける
プログラムをスムーズに動作させるために、次のヒントを考慮してください:
- 適切な場合は大きなページサイズを使用する(Linuxの巨大ページ、Windowsの大きなページ)
- メモリアクセスパターンを局所性に最適化する
- 作業セットサイズに注意を払う
覚えておいてください:幸せなTLBはパフォーマンスの良いプログラムです!
基本を超えて: 高度な仮想メモリ技術
仮想メモリの世界をさらに深く探求すると、いくつかの興味深い高度な技術に出会います:
インバーテッドページテーブル
従来のページテーブルは、特に64ビットシステムでは多くのメモリを消費します。インバーテッドページテーブルは、物理ページを仮想アドレスにマッピングするハッシュテーブルを使用して、ページテーブルのメモリオーバーヘッドを大幅に削減しますが、ルックアップ時間が長くなる可能性があります。
多段ページテーブル
現代のシステムの広大なアドレス空間を処理するために、多段ページテーブルは翻訳プロセスを段階に分けます。例えば、典型的なx86-64システムでは、4段階のページテーブルを使用することがあります:
CR3 → PML4 → PDP → PD → PT → Physical Page
この階層的なアプローチは、効率的なメモリ使用と柔軟なメモリ管理を可能にします。
ASID: フラッシュなしのコンテキストスイッチング
アドレススペース識別子(ASID)は、いくつかのアーキテクチャでTLBを毎回フラッシュすることなくコンテキストスイッチを行うための巧妙なトリックです。TLBエントリにASIDをタグ付けすることで、CPUは複数のプロセスからの翻訳を同時にTLBに保持できます。
struct TLBEntry {
uint64_t virtual_page_number;
uint64_t physical_page_number;
uint16_t asid;
// ... other flags
};
これにより、頻繁なコンテキストスイッチが発生するシステムでのパフォーマンスが大幅に向上します。
仮想メモリの未来
コンピューティングの限界を押し広げる中で、仮想メモリは進化し続けています。今後の興味深い発展には以下のものがあります:
- 異種メモリ管理: DRAM、NVRAM、HBMなど異なるタイプのメモリを組み合わせたシステムの増加に伴い、仮想メモリシステムはこれらの多様なリソースを効率的に管理するように適応しています。
- ハードウェア支援のページテーブルウォーク: 一部の最新のCPUには、ページテーブルを歩くための専用ハードウェアが含まれており、TLBミスのパフォーマンスへの影響をさらに軽減します。
- 機械学習駆動のプリフェッチング: 研究者は、メモリアクセスパターンを予測し、ページをTLBにプリフェッチするためにML技術を活用することを模索しています。
まとめ: 現代コンピューティングの見えないバックボーン
仮想メモリは、ページテーブルとTLBの複雑なダンスで、現代のコンピューティングの見えないバックボーンを形成しています。これは、コンピュータ科学者やエンジニアの創意工夫の証であり、断片化された物理リソースから広大で連続したメモリ空間の幻想を作り出しています。
次にプログラムが実行されるとき、あなたの気ままな仮想アドレスを物理的な現実に変換するために舞台裏で働く複雑な機械に思いを馳せてください。そして、仮想メモリの世界では、何もかもが見た目通りではないことを覚えておいてください。しかし、それこそが仮想メモリを強力にしているのです。
"コンピュータサイエンスでは、私たちは巨人の肩に立っています。そして、その巨人たちは非常に巧妙な仮想メモリの実装の上に立っています。" - 匿名のビットレンジャー
さあ、思い切ってメモリを割り当てましょう。仮想メモリシステムがあなたを支えています!