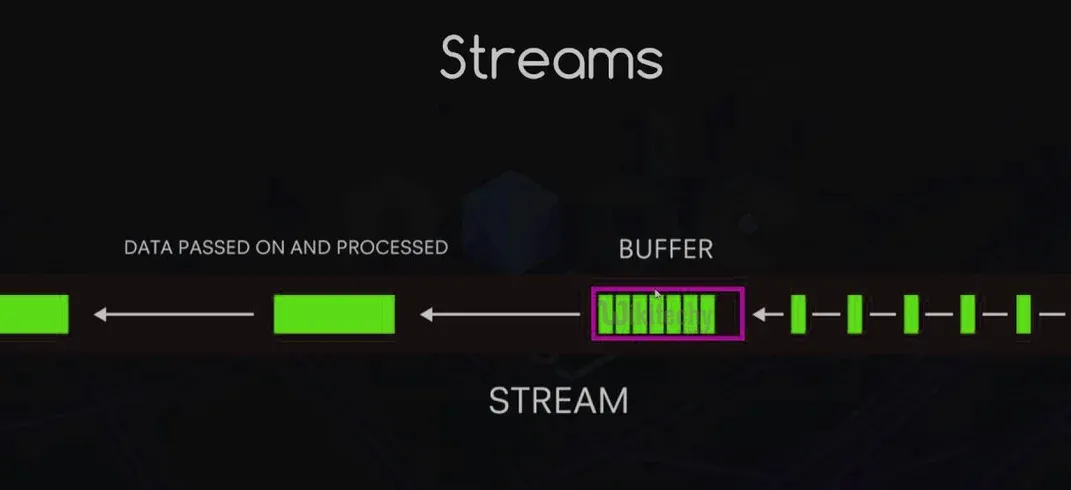
ストリームを使うと、データを一度にすべてメモリに読み込むことなく、少しずつ読み書きできます。これは、大量のデータやリアルタイム情報を扱うときに非常に重要です。
でも、なぜ気にする必要があるのでしょうか?例えば、次のNetflixを作ると想像してみてください。ユーザーが動画をすぐに見始められるようにしたいですよね。ファイル全体をダウンロードするのを待つ必要はありません。そこでストリームが役立ちます。データを小さなチャンクで処理できるので、アプリがより効率的で応答性が高くなります。
ストリームの種類: 自分に合ったものを選ぼう
Node.jsは4種類のストリームを提供しており、それぞれに特別な機能があります:
- Readable: データを読むためのものです。アプリの目のようなものです。
- Writable: データを書くためのものです。アプリのペンのようなものです。
- Duplex: 読み書きの両方ができます。目とペンを同時に持っているようなものです。
- Transform: データを転送中に変更できる特別なDuplexストリームです。アプリの脳のように、情報を即座に処理します。
ストリームの仕組み: データフローの基本
工場のコンベアベルトを想像してみてください。データのチャンクがこのベルトに沿って移動し、一度に1つずつ処理されます。これがストリームの基本的な動作です。データが流れるときにイベントを発生させ、プロセスのさまざまな部分にフックすることができます。
主なイベントの概要は次のとおりです:
data: 読み取るデータが利用可能になったときに発生します。end: すべてのデータが読み取られたことを示します。error: 問題が発生したときに発生します。finish: すべてのデータが基盤システムにフラッシュされたことを示します。
ストリームを使う利点: なぜ使うべきか
ストリームを使うことは、単にかっこいいだけではありません(もちろん、それもありますが)。以下のような理由があります:
- メモリ効率: 大量のデータを処理しても、すべてのRAMを消費しません。
- 時間効率: データをすぐに処理し始めることができ、すべてのデータが読み込まれるのを待つ必要がありません。
- 合成性: ストリームを簡単に組み合わせて、強力なデータパイプラインを作成できます。
- 組み込みのバックプレッシャー: データフローの速度を自動的に管理し、宛先を圧倒しないようにします。
ReadableとWritableストリームの実装: コードタイム!
コードを実際に書いてみましょう。まず、シンプルなReadableストリームを作成します:
const { Readable } = require('stream');
class CounterStream extends Readable {
constructor(max) {
super();
this.max = max;
this.index = 1;
}
_read() {
const i = this.index++;
if (i > this.max) {
this.push(null);
} else {
const str = String(i);
const buf = Buffer.from(str, 'ascii');
this.push(buf);
}
}
}
const counter = new CounterStream(5);
counter.on('data', (chunk) => console.log(chunk.toString()));
counter.on('end', () => console.log('Finished counting!'));
このReadableストリームは1から5までカウントします。次に、数値を2倍にするWritableストリームを作成します:
const { Writable } = require('stream');
class DoubleStream extends Writable {
_write(chunk, encoding, callback) {
console.log(Number(chunk.toString()) * 2);
callback();
}
}
const doubler = new DoubleStream();
counter.pipe(doubler);
これを実行すると、2, 4, 6, 8, 10が出力されます。まるで魔法のようです!
DuplexとTransformストリームの操作: 双方向の通り
Duplexストリームは電話の会話のようなもので、データが両方向に流れます。簡単な例を示します:
const { Duplex } = require('stream');
class DuplexStream extends Duplex {
constructor(options) {
super(options);
this.data = ['a', 'b', 'c', 'd'];
}
_read(size) {
if (this.data.length) {
this.push(this.data.shift());
} else {
this.push(null);
}
}
_write(chunk, encoding, callback) {
console.log(chunk.toString().toUpperCase());
callback();
}
}
const duplex = new DuplexStream();
duplex.on('data', (chunk) => console.log('Read:', chunk.toString()));
duplex.write('1');
duplex.write('2');
duplex.write('3');
Transformストリームは、内蔵のプロセッサを持つDuplexストリームのようなものです。小文字を大文字に変換する例を示します:
const { Transform } = require('stream');
class UppercaseTransform extends Transform {
_transform(chunk, encoding, callback) {
this.push(chunk.toString().toUpperCase());
callback();
}
}
const upperCaser = new UppercaseTransform();
process.stdin.pipe(upperCaser).pipe(process.stdout);
これを実行して、小文字のテキストを入力してみてください。大文字に変換される様子を見てみましょう!
ストリームイベントの処理: すべてのアクションをキャッチ
ストリームはさまざまなイベントを発生させ、それをリッスンして処理することができます。簡単な説明を示します:
const fs = require('fs');
const readStream = fs.createReadStream('hugefile.txt');
readStream.on('data', (chunk) => {
console.log(`Received ${chunk.length} bytes of data.`);
});
readStream.on('end', () => {
console.log('Finished reading the file.');
});
readStream.on('error', (err) => {
console.error('Oh no, something went wrong!', err);
});
readStream.on('close', () => {
console.log('Stream has been closed.');
});
ストリームパイプライン: データハイウェイを構築
パイプラインを使うと、ストリームを簡単に連結できます。データのためのルーブ・ゴールドバーグ・マシンを作るようなものです!例を示します:
const { pipeline } = require('stream');
const fs = require('fs');
const zlib = require('zlib');
pipeline(
fs.createReadStream('input.txt'),
zlib.createGzip(),
fs.createWriteStream('input.txt.gz'),
(err) => {
if (err) {
console.error('Pipeline failed', err);
} else {
console.log('Pipeline succeeded');
}
}
);
このパイプラインはファイルを読み込み、圧縮し、新しいファイルに圧縮データを書き込みます。すべてがスムーズに行われます!
バッファリング対ストリーミング: 対決
食べ放題のビュッフェを想像してみてください。バッファリングは、食べる前に皿をいっぱいにするようなもので、ストリーミングは一口ずつ食べるようなものです。どちらを使うべきか:
- バッファリングを使うとき:
- データセットが小さいとき
- データへのランダムアクセスが必要なとき
- データセット全体を必要とする操作を行うとき
- ストリーミングを使うとき:
- 大規模なデータセットを扱うとき
- リアルタイムデータを処理するとき
- スケーラブルでメモリ効率の良いアプリケーションを構築するとき
バックプレッシャーの管理: パイプを破裂させないで!
バックプレッシャーは、データが処理されるよりも速く入ってくるときに発生します。これは、1ガロンの水をパイントグラスに注ごうとするようなもので、混乱が生じます。Node.jsのストリームには組み込みのバックプレッシャー処理がありますが、手動で管理することもできます:
const writable = getWritableStreamSomehow();
const readable = getReadableStreamSomehow();
readable.on('data', (chunk) => {
if (!writable.write(chunk)) {
readable.pause();
}
});
writable.on('drain', () => {
readable.resume();
});
このコードは、WritableストリームのバッファがいっぱいになったときにReadableストリームを一時停止し、バッファが空になったときに再開します。
実際のアプリケーション: ストリームの活用
ストリームは単なる面白いトリックではありません。実際のアプリケーションで頻繁に使用されています。いくつかの例を示します:
- ファイル処理: 大規模なログファイルの読み書き
- メディアストリーミング: ビデオやオーディオコンテンツの配信
- データのインポート/エクスポート: 大規模なCSVファイルの処理
- リアルタイムデータ処理: ソーシャルメディアフィードの分析
パフォーマンスの最適化: ストリームを高速化
ストリームをさらに速くしたいですか?以下のヒントを参考にしてください:
- バイナリデータには
Bufferを使用する - スループットを向上させるために
highWaterMarkを増やす(ただしメモリ使用量に注意) Cork()とuncork()を使って書き込みをバッチ処理する- より効率的なバッチ書き込みのためにカスタム
_writev()を実装する
デバッグとエラーハンドリング: ストリームがうまくいかないとき
ストリームのデバッグは難しいことがあります。以下の戦略を試してみてください:
debugモジュールを使ってストリームイベントをログに記録する- 常に
'error'イベントを処理する stream.finished()を使ってストリームが終了したかエラーが発生したかを検出する
const { finished } = require('stream');
const fs = require('fs');
const rs = fs.createReadStream('file.txt');
finished(rs, (err) => {
if (err) {
console.error('Stream failed', err);
} else {
console.log('Stream is done reading');
}
});
rs.resume(); // ストリームをドレインする
ツールとライブラリ: ストリームを強化
ストリームをさらに簡単に扱うためのライブラリがたくさんあります。いくつか紹介します:
- through2: ストリーム構築を簡素化
- concat-stream: 文字列やバイナリデータを連結するWritableストリーム
- get-stream: ストリームを文字列、バッファ、または配列として取得
- into-stream: バッファ/文字列/配列/オブジェクトをストリームに変換
結論: ストリームの力
Node.jsのストリームは、開発者のツールキットにおける秘密の武器のようなものです。データを効率的に処理し、大規模なデータセットを簡単に扱い、スケーラブルなアプリケーションを構築することができます。ストリームをマスターすることで、Node.jsの機能を学ぶだけでなく、データ処理の強力なパラダイムを採用することになります。
大きな力には大きな責任が伴います。ストリームを賢く使い、データが常にスムーズに流れることを願っています!
"私はストリーム、あなたはストリーム、私たちはみんな...効率的なデータ処理のためにストリーム!" - 匿名のNode.js開発者
さあ、すべてのものをストリームしましょう!🌊💻