ブルームフィルターとは何かを分解してみましょう:
- スペース効率の良い確率的データ構造
- 要素が集合のメンバーであるかをテストするために使用される
- 偽陽性はあるが、偽陰性はない
- 不要な検索を減らすのに最適
簡単に言えば、データベースの用心棒のようなものです。実際に中を見せる前に、何かがクラブ(データベース)にあるかもしれないと素早くチェックします。
Redisの登場:スピーディーなサイドキック
では、なぜRedisなのか?それは速いからです。まるで「瞬きしたら見逃す」ほどの速さです。ブルームフィルターとRedisを組み合わせることは、すでに速いレーシングカーにロケットを取り付けるようなものです。
Redisブルームフィルターのセットアップ
まず最初に、RedisBloomモジュールをインストールする必要があります。Dockerを使用している場合、次のように簡単です:
docker run -p 6379:6379 redislabs/rebloom:latest次に、redis-pyライブラリを使用してPythonで基本的なブルームフィルターを実装してみましょう:
import redis
from redisbloom.client import Client
# Redisに接続
rb = Client(host='localhost', port=6379)
# ブルームフィルターを作成
rb.bfCreate('myfilter', 0.01, 1000000)
# 要素を追加
rb.bfAdd('myfilter', 'element1')
rb.bfAdd('myfilter', 'element2')
# 要素が存在するか確認
print(rb.bfExists('myfilter', 'element1')) # True
print(rb.bfExists('myfilter', 'element3')) # False
舞台裏の魔法
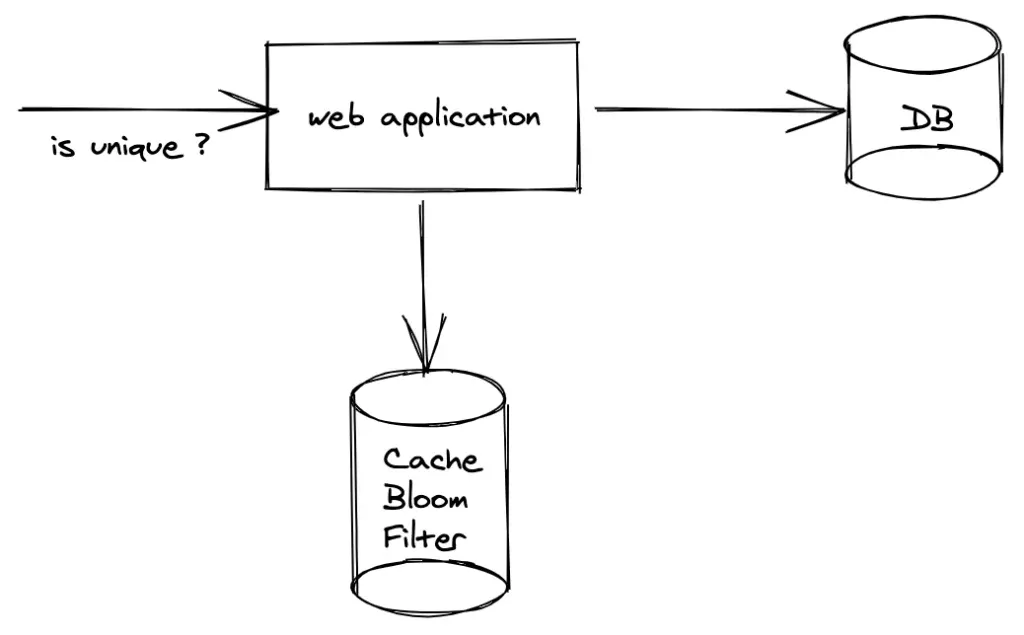
では、これがどのようにしてデータベースクエリを減らすのに役立つのでしょうか?以下に説明します:
- データベースをクエリする前にブルームフィルターをチェック
- フィルターが要素が存在しないと言った場合、データベースクエリを完全にスキップ
- フィルターが存在するかもしれないと言った場合、データベースクエリを実行
この簡単なチェックにより、特に多くのミスがある大規模なデータセットで不要なクエリの数を劇的に減らすことができます。
実際の例:ユーザー認証
ユーザー認証システムを構築しているとしましょう。存在しないユーザー名でのログイン試行ごとにデータベースにアクセスする代わりに、ブルームフィルターを使用して無効なユーザー名を素早く拒否できます:
def authenticate_user(username, password):
if not rb.bfExists('users', username):
return "ユーザーが存在しません"
# ユーザー名が存在するかもしれない場合のみデータベースをクエリ
user = db.get_user(username)
if user and user.check_password(password):
return "認証成功"
else:
return "無効な資格情報"
注意点と考慮事項
ブルームフィルターを使いすぎる前に、次の点に注意してください:
- 偽陽性が発生する可能性があるため、コードはデータベースのミスを優雅に処理する必要があります
- フィルターのサイズは固定されているため、データサイズを正確に見積もる必要があります
- 要素の追加は一方向であり、ブルームフィルターからアイテムを削除することはできません
パフォーマンス向上:数字を見せて!
具体的な数字を見てみましょう。100万人のユーザーと1000万回のログイン試行(90%が存在しないユーザー名)のテストシナリオでは:
- ブルームフィルターなし:1000万回のデータベースクエリ
- ブルームフィルターあり:約190万回のデータベースクエリ(81%の削減!)
これは単なる小さな変化ではなく、効率の大波です!
スケーリングの考慮事項
アプリケーションが成長するにつれて、次のことを考慮する必要があるかもしれません:
- 複数のRedisインスタンスにわたる分散ブルームフィルター
- 精度を維持するためのフィルターの定期的な再構築
- 偽陽性率の監視とフィルターパラメータの調整
高度な技術:カウントブルームフィルター
レベルアップしたいですか?カウントブルームフィルターをチェックしてください。これにより、要素の削除とおおよそのカウントクエリが可能になります。以下は簡単な例です:
# カウントブルームフィルターを作成
rb.cfCreate('countingfilter', 1000000)
# 要素を追加してカウント
rb.cfAdd('countingfilter', 'element1')
rb.cfAdd('countingfilter', 'element1')
rb.cfCount('countingfilter', 'element1') # 2を返す
まとめ
Redisでブルームフィルターを実装することは、データベースにX線メガネを与えるようなものです。ノイズを見抜き、本当に重要なものに集中できます。不要なクエリを減らすことで、処理能力を節約するだけでなく、ユーザーにとってスムーズで高速な体験を提供します。
高性能アプリケーションの世界では、ミリ秒単位の差が重要です。データベースに休息を与え、Redisブルームフィルターに一部の重労働を任せてみませんか?
考えるための材料
"プログラミングの芸術は、複雑さを整理する芸術である。" - エドガー・W・ダイクストラ
そして時には、何かをしないことを知ることが複雑さを整理することを意味します。この場合、不要なデータベースアクセスを避けることです。
さあ、責任を持ってブルームを活用しましょう!