私たちは、LangChainを使用して、大規模言語モデル(LLM)の力とベクターデータベースの精度を組み合わせたバックエンドを構築します。その結果は?コンテキストを理解し、関連情報を取得し、人間のような応答を即座に生成するAPIです。それはただ賢いだけでなく、驚くほど賢いのです。
RAG革命:なぜ注目すべきか?
コードを書く前に、なぜRAGがAIの世界で注目されているのかを説明しましょう:
- コンテキストが重要:RAGシステムは、従来のキーワードベースの検索よりもコンテキストを理解し活用します。
- 新鮮で関連性のある情報:静的なLLMとは異なり、RAGは最新の情報にアクセスして使用できます。
- 幻覚の削減:取得したデータに基づいて応答を生成することで、RAGはAIの幻覚を減少させます。
- スケーラビリティ:データが増えるにつれて、AIの知識も増え、再トレーニングが不要です。
技術スタック:私たちの選択
手ぶらで戦いに挑むわけではありません。これが私たちの武器です:
- LangChain:LLM操作のための万能ツール
- ベクターデータベース:Pineconeを使用しますが、お気に入りのものに置き換えても構いません
- LLM:OpenAIのGPT-3.5またはGPT-4(またはお好みのLLM)
- FastAPI:高速なAPIエンドポイントを構築するため
- Python:なぜなら、Pythonだからです
プレイグラウンドの設定
まず最初に、環境を整えましょう。ターミナルを開いて、必要なパッケージをインストールします:
pip install langchain pinecone-client openai fastapi uvicorn
次に、基本的なFastAPIアプリの構造を作成します:
from fastapi import FastAPI
from langchain import OpenAI, VectorDBQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
import os
app = FastAPI()
# Pineconeの初期化
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
# OpenAIの初期化
llm = OpenAI(temperature=0.7)
# 埋め込みの初期化
embeddings = OpenAIEmbeddings()
# Pineconeベクトルストアの初期化
index_name = "your-pinecone-index-name"
vectorstore = Pinecone.from_existing_index(index_name, embeddings)
# QAチェーンの初期化
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", vectorstore=vectorstore)
@app.get("/")
async def root():
return {"message": "RAG搭載APIへようこそ!"}
@app.get("/query")
async def query(q: str):
result = qa.run(q)
return {"result": result}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
詳細解説:ここで何が起こっているのか?
このコードを高校の生物の授業でカエルを解剖するように分解してみましょう(でももっと面白いです):
- FastAPIをウェブフレームワークとして設定しています。
- LangChainの
OpenAIクラスがLLMへのゲートウェイです。 VectorDBQAは、ベクターデータベースとLLMを組み合わせて質問応答を行う魔法の杖です。- Pineconeをベクターデータベースとして使用していますが、WeaviateやMilvusなどの代替品に置き換えることもできます。
/queryエンドポイントはRAGの魔法が起こる場所です。質問を受け取り、QAチェーンを通して実行し、結果を返します。
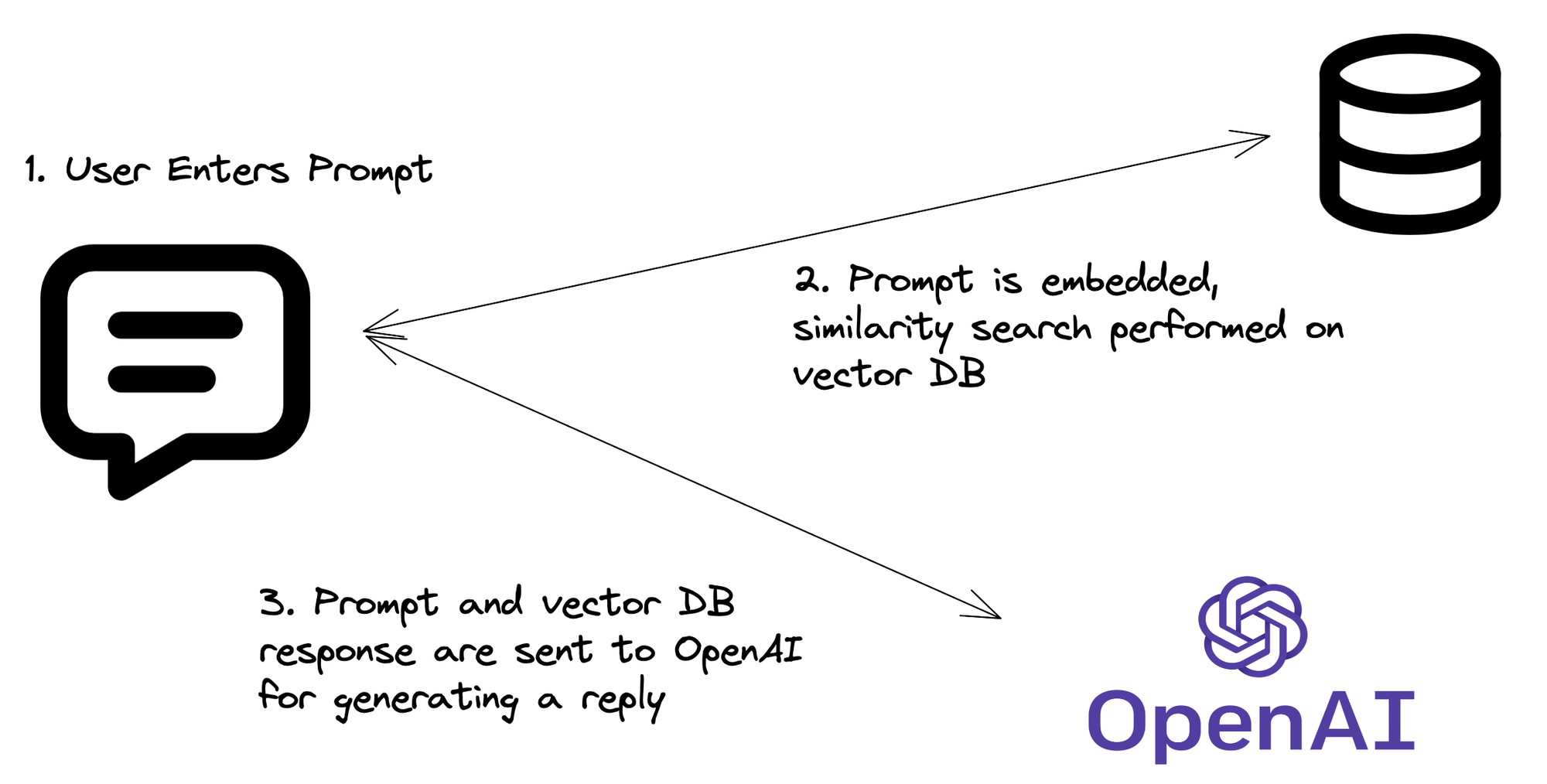
RAGパイプライン:実際の動作
コードが揃ったので、RAGプロセスを分解してみましょう:
- クエリ埋め込み:APIが質問を受け取り、それをベクトル埋め込みに変換します。
- ベクトル検索:この埋め込みを使用して、Pineconeインデックスで類似のベクトル(つまり関連情報)を検索します。
- コンテキスト取得:Pineconeから最も関連性の高いドキュメントやチャンクを取得します。
- LLMの魔法:元の質問と取得したコンテキストをLLMに送信します。
- 応答生成:LLMは質問と取得したコンテキストに基づいて応答を生成します。
- APIの返却:APIはこの知的でコンテキストに基づいた応答を返します。
RAGを強化する:高度な技術
RAGシステムを「かなりクール」から「すごい!」にする準備はできましたか?次の高度な技術を試してみてください:
1. ハイブリッド検索
ベクトル検索と従来のキーワード検索を組み合わせて、さらに良い結果を得ましょう:
from langchain.retrievers import PineconeHybridSearchRetriever
hybrid_retriever = PineconeHybridSearchRetriever(
embeddings=embeddings,
index=vectorstore.pinecone_index
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=hybrid_retriever)
2. 再ランキング
取得したドキュメントを微調整するために再ランキングステップを実装します:
from langchain.retrievers import RePhraseQueryRetriever
rephraser = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=rephraser)
3. ストリーミング応答
よりインタラクティブな体験のために、API応答をストリーミングします:
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
@app.get("/stream")
async def stream_query(q: str):
async def event_generator():
for token in qa.run(q):
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
潜在的な落とし穴:注意すべき点
RAGは素晴らしいですが、いくつかの注意点があります。以下の点に注意してください:
- コンテキストウィンドウの制限:LLMには最大コンテキストサイズがあります。取得したドキュメントがこれを超えないように注意してください。
- 関連性と多様性のバランス:関連性のある結果と多様な情報のバランスを取るのは難しい場合があります。取得パラメータを試行錯誤してください。
- 幻覚は完全には消えない:RAGは幻覚を減少させますが、完全には排除しません。常に安全策と事実確認のメカニズムを実装してください。
- APIコスト:各クエリは複数のAPIコール(埋め込み、ベクトル検索、LLM)を含む可能性があります。請求書に注意してください!
まとめ:なぜこれが重要なのか
バックエンドにRAGを実装することは、最先端であることだけでなく(それも素晴らしいボーナスですが)、より知的でコンテキストに基づいたアプリケーションを作成することです。これにより、ユーザーのクエリを以前は不可能だった方法で理解し、応答することができます。
LLMの広範な知識とベクターデータベースの具体的で最新の情報を組み合わせることで、部分の合計を超えるシステムを作成しています。それは、APIに超能力を与えるようなものです。リアルタイムデータに基づいて理解し、推論し、人間のような応答を生成する能力です。
"未来はすでにここにあるが、それは均等に分配されていない。" - ウィリアム・ギブソン
さて、あなたはその未来の一部を手に入れた幸運な一人です。素晴らしいものを作りましょう!
考えるための材料
プロジェクトにRAGを実装する際、次の質問を考慮してください:
- RAGシステムで使用されるデータのプライバシーとセキュリティをどのように確保しますか?
- AI搭載のAPIを展開する際にどのような倫理的考慮が必要ですか?
- LLMとベクターデータベースが進化するにつれて、RAGシステムはどのように進化するでしょうか?
これらの質問への答えは、AI搭載アプリケーションの未来を形作るでしょう。そして今、あなたはその革命の最前線にいます。コーディングを楽しんでください!