要約
Kafkaで冪等性のあるコンシューマを実装することは、データの一貫性を確保し、重複処理を防ぐために重要です。この記事では、ベストプラクティス、一般的な落とし穴、そしてKafkaコンシューマを数学的関数のように冪等にするためのいくつかの便利なトリックを探ります。
冪等性が重要な理由
詳細に入る前に、なぜ冪等性が重要なのかを簡単に振り返りましょう:
- メッセージの重複処理を防ぐ
- システム全体のデータの一貫性を確保する
- 夜中のデバッグやストレスから解放される
- システムを障害や再試行に対してより強靭にする
それでは、具体的な内容に入りましょう!
冪等性のあるコンシューマを実装するためのベストプラクティス
1. ユニークなメッセージ識別子を使用する
冪等性のあるコンシューマの第一のルールは、常にユニークなメッセージ識別子を使用することです。(第二のルールは...まあ、わかりますよね。)
これを実装するのは簡単です:
public class KafkaMessage {
private String id;
private String payload;
// ... 他のフィールドやメソッド
}
public class IdempotentConsumer {
private Set processedMessageIds = new HashSet<>();
public void consume(KafkaMessage message) {
if (processedMessageIds.add(message.getId())) {
// メッセージを処理する
processMessage(message);
} else {
// メッセージはすでに処理済み、スキップする
log.info("重複メッセージをスキップ: {}", message.getId());
}
}
}
プロのヒント: メッセージIDにはUUIDやトピック、パーティション、オフセットの組み合わせを使用しましょう。まるで各メッセージにユニークな雪の結晶パターンを与えるようなものです!
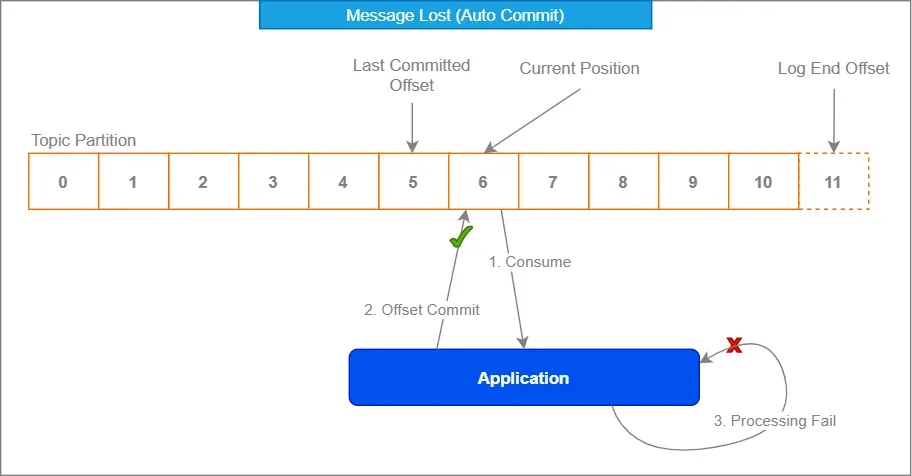
2. Kafkaのオフセット管理を活用する
Kafkaの組み込みオフセット管理はあなたの味方です。最初はぎこちなく感じるかもしれませんが、頼りになる存在です。
Properties props = new Properties();
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed");
KafkaConsumer consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
processRecord(record);
}
consumer.commitSync();
}
自動コミットを無効にし、処理後に手動でオフセットをコミットすることで、メッセージが確実に正しく処理されたときにのみ消費済みとしてマークされるようにします。
3. 重複排除戦略を実装する
最善を尽くしても、重複は忍者のように忍び寄ってくることがあります。そこで、しっかりとした重複排除戦略が役立ちます。
Redisのような分散キャッシュを使用して、処理済みメッセージIDを保存することを検討してください:
@Service
public class DuplicateChecker {
private final RedisTemplate redisTemplate;
public DuplicateChecker(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean isDuplicate(String messageId) {
return !redisTemplate.opsForValue().setIfAbsent(messageId, "processed", Duration.ofDays(1));
}
}
このアプローチにより、複数のコンシューマインスタンス間や再起動後でも重複をチェックできます。まるでメッセージのためのバウンサーのようです。「IDがリストにないなら、入れません!」
4. 冪等性のある操作を使用する
可能な限り、メッセージ処理操作を自然に冪等性のあるものに設計しましょう。これにより、メッセージが複数回処理されても、最終結果に影響を与えません。
例えば、次のようにする代わりに:
public void incrementCounter(String counterId) {
int currentValue = counterRepository.get(counterId);
counterRepository.set(counterId, currentValue + 1);
}
次のような原子的な操作を使用することを検討してください:
public void incrementCounter(String counterId) {
counterRepository.increment(counterId);
}
この方法では、同じメッセージに対してインクリメント操作が複数回呼び出されても、最終結果は同じになります。
一般的な落とし穴とその回避方法
基本をカバーしたところで、経験豊富な開発者でも陥りがちな一般的な罠を見てみましょう:
1. Kafkaの「一度だけ」セマンティクスにのみ依存する
Kafkaは「一度だけ」セマンティクスを提供しますが、万能ではありません。これはKafkaクラスター内での一度だけの配信を保証するものであり、アプリケーション全体での一度だけの処理を保証するものではありません。
「信頼せよ、しかし確認せよ」 – ロナルド・レーガン(おそらくKafkaメッセージについて話していた)
Kafkaの保証に加えて、独自の冪等性チェックを常に実装してください。
2. トランザクション境界を無視する
メッセージ処理とオフセットコミットが同じトランザクションの一部であることを確認してください。そうしないと、メッセージを処理したがオフセットをコミットしていない状況に陥り、コンシューマの再起動時に再処理される可能性があります。
@Transactional
public void processMessage(ConsumerRecord record) {
// メッセージを処理する
businessLogic.process(record.value());
// メッセージを手動で確認する
acknowledgment.acknowledge();
}
3. データベース制約を見落とす
処理済みデータをデータベースに保存する場合、ユニーク制約を活用してください。これにより、重複に対する追加の保護層として機能します。
CREATE TABLE processed_messages (
message_id VARCHAR(255) PRIMARY KEY,
processed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
そして、Javaコードでは次のようにします:
try {
jdbcTemplate.update("INSERT INTO processed_messages (message_id) VALUES (?)", messageId);
// メッセージを処理する
} catch (DuplicateKeyException e) {
// メッセージはすでに処理済み、スキップする
}
勇敢な人のための高度な技術
冪等性のあるコンシューマのスキルを次のレベルに引き上げる準備はできましたか?ここでは、挑戦的な人のための高度な技術を紹介します:
1. ヘッダーに冪等性キーを使用する
メッセージの内容に依存する代わりに、Kafkaメッセージのヘッダーに冪等性キーを保存することを検討してください。これにより、メッセージの内容を柔軟にしつつ、冪等性を維持できます。
// プロデューサー
ProducerRecord record = new ProducerRecord<>("my-topic", "key", "value");
record.headers().add("idempotency-key", UUID.randomUUID().toString().getBytes());
producer.send(record);
// コンシューマー
ConsumerRecord record = // ... Kafkaから受信
byte[] idempotencyKeyBytes = record.headers().lastHeader("idempotency-key").value();
String idempotencyKey = new String(idempotencyKeyBytes, StandardCharsets.UTF_8);
2. 時間ベースの重複排除
特定のシナリオでは、時間ベースの重複排除を実装することを検討してください。これは、同じイベントが一定期間後に正当に繰り返される可能性があるイベントストリームを扱う場合に役立ちます。
public class TimeBasedDuplicateChecker {
private final RedisTemplate redisTemplate;
private final Duration deduplicationWindow;
public TimeBasedDuplicateChecker(RedisTemplate redisTemplate, Duration deduplicationWindow) {
this.redisTemplate = redisTemplate;
this.deduplicationWindow = deduplicationWindow;
}
public boolean isDuplicate(String messageId) {
String key = "dedup:" + messageId;
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(key, "processed", deduplicationWindow);
return isNew != null && !isNew;
}
}
3. 冪等性のある集計
集計操作を扱う場合、冪等性のある集計技術を使用することを検討してください。例えば、累積和を保存する代わりに、個々の値を保存し、オンザフライで合計を計算します:
public class IdempotentAggregator {
private final Map values = new ConcurrentHashMap<>();
public void addValue(String key, double value) {
values.put(key, value);
}
public double getSum() {
return values.values().stream().mapToDouble(Double::doubleValue).sum();
}
}
このアプローチにより、メッセージが複数回処理されても、最終的な集計結果に影響を与えません。
まとめ
Kafkaで冪等性のあるコンシューマを実装することは難しい作業に思えるかもしれませんが、これらのベストプラクティスと技術を使用すれば、すぐに重複をプロのように扱えるようになります。重要なのは、常に予期せぬ事態を想定し、最初から冪等性を考慮してシステムを設計することです。
以下は、手元に置いておくための簡単なチェックリストです:
- ユニークなメッセージ識別子を使用する
- Kafkaのオフセット管理を活用する
- 堅牢な重複排除戦略を実装する
- 可能な限り自然に冪等性のある操作を設計する
- 一般的な落とし穴とその回避方法を知る
- 特定のユースケースに対して高度な技術を検討する
これらのガイドラインに従うことで、Kafkaベースのシステムの信頼性と一貫性を向上させるだけでなく、デバッグや頭痛の時間を大幅に節約できます。そして正直なところ、それが私たち全員が求めていることではないでしょうか?
さあ、重複メッセージを征服しに行きましょう!未来の自分(と運用チーム)が感謝することでしょう。
「Kafkaコンシューマの世界では、冪等性は単なる機能ではなく、スーパーパワーです。」 – ある賢い開発者(おそらく)
コーディングを楽しんでください。そして、あなたのコンシューマが常に冪等でありますように!