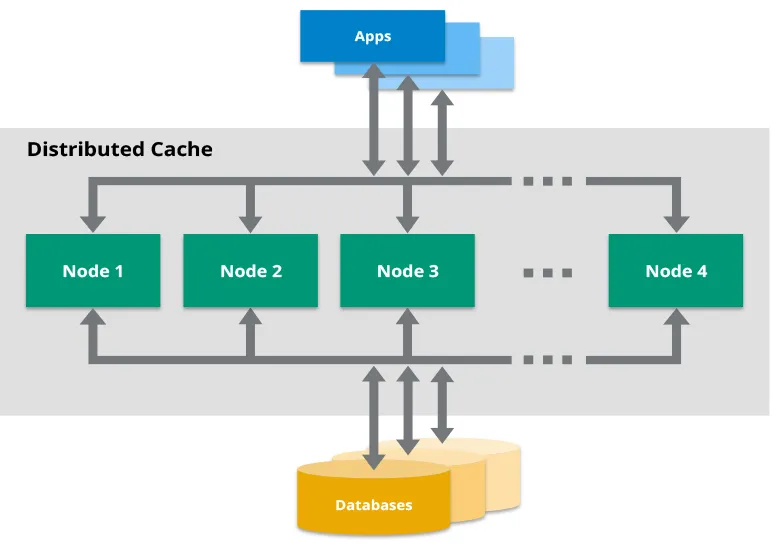
なぜHazelcastなのか?そして、なぜ気にするべきなのか?
詳細に入る前に、まずは大きな疑問に答えましょう:なぜHazelcastなのか?キャッシングソリューションの広大な海の中で、HazelcastはJavaと相性の良い分散インメモリデータグリッドとして際立っています。Redisのようですが、Javaを第一に考えたアプローチと、マイクロサービスでの分散キャッシングを簡単にするいくつかの便利な機能を備えています。
Hazelcastがあなたの新しい親友になるかもしれない理由を簡単に紹介します:
- ネイティブJava API(シリアライズに悩まされることはありません)
- 分散計算(MapReduceのようですが、もっと簡単です)
- ビルトインのスプリットブレイン保護(ネットワーク分割は起こるものです)
- 簡単なスケーリング(ノードを追加するだけです)
マイクロサービスでのHazelcastのセットアップ
基本から始めましょう。JavaマイクロサービスにHazelcastを追加するのは驚くほど簡単です。まず、pom.xmlに依存関係を追加します:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.1.1</version>
</dependency>
次に、シンプルなHazelcastインスタンスを作成しましょう:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class CacheConfig {
public HazelcastInstance hazelcastInstance() {
return Hazelcast.newHazelcastInstance();
}
}
これで、マイクロサービス内でHazelcastノードが動作しています。しかし、まだまだ続きます!
高度なキャッシングパターン
基本をカバーしたところで、マイクロサービスをさらに活用するための高度なキャッシングパターンに進みましょう。
1. リードスルー/ライトスルーキャッシング
このパターンは、データのための個人アシスタントを持つようなものです。キャッシュに何を出し入れするかを手動で管理する代わりに、Hazelcastがそれを代わりに行ってくれます。
public class UserCacheStore implements MapStore<String, User> {
@Override
public User load(String key) {
// データベースからロード
}
@Override
public void store(String key, User value) {
// データベースに保存
}
// その他のメソッド...
}
MapConfig mapConfig = new MapConfig("users");
mapConfig.setMapStoreConfig(new MapStoreConfig().setImplementation(new UserCacheStore()));
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
このセットアップにより、Hazelcastはキャッシュにないデータを自動的にデータベースからロードし、キャッシュで更新されたデータをデータベースに書き戻します。まるで魔法のようですが、実際には優れたエンジニアリングです。
2. ニアキャッシュパターン
時には、分散環境でもデータを非常に高速にする必要があります。そこでニアキャッシュパターンの登場です。キャッシュのためのキャッシュを持つようなものです。メタですね?
NearCacheConfig nearCacheConfig = new NearCacheConfig();
nearCacheConfig.setName("users");
nearCacheConfig.setTimeToLiveSeconds(300);
MapConfig mapConfig = new MapConfig("users");
mapConfig.setNearCacheConfig(nearCacheConfig);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
このセットアップは、各Hazelcastノードにローカルキャッシュを作成し、ネットワーク呼び出しを減らし、読み取り操作を高速化します。頻繁に読み取られるが、あまり更新されないデータに特に有用です。
3. エビクションポリシー
メモリは貴重です、特にマイクロサービスでは。Hazelcastは、キャッシュがメモリを圧迫しないようにするための高度なエビクションポリシーを提供します。
MapConfig mapConfig = new MapConfig("users");
mapConfig.setEvictionConfig(
new EvictionConfig()
.setEvictionPolicy(EvictionPolicy.LRU)
.setMaxSizePolicy(MaxSizePolicy.PER_NODE)
.setSize(10000)
);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
この設定は、LRU(最も最近使用されていない)エビクションポリシーを設定し、キャッシュがノードごとに10,000エントリの制限内に収まるようにします。データパーティーのためのバウンサーのように、混雑しすぎたときに最も人気のないエントリを追い出します。
分散計算:次のレベルへ
キャッシングは素晴らしいですが、Hazelcastはそれ以上のことができます。分散計算を活用してマイクロサービスを強化する方法を見てみましょう。
1. 分散エグゼキュータサービス
クラスター全体でタスクを実行する必要がありますか?Hazelcastの分散エグゼキュータサービスがサポートします。
public class UserAnalytics implements Callable<Map<String, Integer>>, HazelcastInstanceAware {
private transient HazelcastInstance hazelcastInstance;
@Override
public Map<String, Integer> call() {
IMap<String, User> users = hazelcastInstance.getMap("users");
// ローカルデータで分析を実行
return results;
}
@Override
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
}
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IExecutorService executorService = hz.getExecutorService("analytics-executor");
Set<Member> members = hz.getCluster().getMembers();
Map<Member, Future<Map<String, Integer>>> results = executorService.submitToMembers(new UserAnalytics(), members);
// 結果を集約
Map<String, Integer> finalResults = new HashMap<>();
for (Future<Map<String, Integer>> future : results.values()) {
Map<String, Integer> result = future.get();
// 結果をfinalResultsにマージ
}
このパターンにより、データが存在する場所で計算を実行でき、データの移動を減らし、パフォーマンスを向上させます。データを関数に持ってくるのではなく、関数をデータに持っていくようなものです。
2. エントリープロセッサ
キャッシュ内の複数のエントリを原子的に更新する必要がありますか?エントリープロセッサが役立ちます。
public class UserUpgradeEntryProcessor implements EntryProcessor<String, User, Object> {
@Override
public Object process(Map.Entry<String, User> entry) {
User user = entry.getValue();
if (user.getPoints() > 1000) {
user.setStatus("GOLD");
entry.setValue(user);
}
return null;
}
}
IMap<String, User> users = hz.getMap("users");
users.executeOnEntries(new UserUpgradeEntryProcessor());
このパターンにより、明示的なロックやトランザクション管理を必要とせずに、複数のエントリに対して操作を実行できます。キャッシュ内の各エントリに対するミニトランザクションを持つようなものです。
注意すべき落とし穴
強力なツールには、独自の潜在的な落とし穴が伴います。ここでは、いくつかの注意点を紹介します:
- 過剰なキャッシング:すべてをキャッシュする必要はありません。Hazelcastに入れるものを選択的にしましょう。
- シリアライズの無視:Hazelcastはオブジェクトをシリアライズする必要があります。オブジェクトがシリアライズ可能であることを確認し、複雑なオブジェクトにはカスタムシリアライザを検討してください。
- モニタリングの怠り:Hazelcastクラスターの適切なモニタリングを設定しましょう。Hazelcast Management Centerのようなツールは非常に役立ちます。
- 一貫性の忘却:分散システムでは、最終的な一貫性が通常の状態です。アプリケーションをそのように設計しましょう。
まとめ
基本的なセットアップから高度なキャッシングパターン、分散計算まで、多くのことをカバーしました。Hazelcastは、Javaマイクロサービスのパフォーマンスとスケーラビリティを大幅に向上させる強力なツールです。しかし、強力な力には大きな責任が伴います。これらのパターンを賢く使用し、常にアプリケーションの特定のニーズを考慮してください。
さあ、プロのようにキャッシュを活用しましょう!あなたのマイクロサービス(とユーザー)が感謝するでしょう。
「最速のデータアクセスは、アクセスする必要のないデータです。」 - 不明なキャッシングの達人(おそらく)
さらなる学び
もっと知りたい方は、以下のリソースをチェックしてください:
ハッピーキャッシング!