イベント駆動型システム、特にKafkaを使用する場合の効果的なエラーハンドリングには、トピック間でコンテキストを意識した失敗を伝播することが必要です。エラーコンテキストを維持し、エラーイベントを設計し、堅牢なエラーハンドリングパターンを実装するための戦略を探ります。この記事を読み終える頃には、分散エラーの混乱を抑え、システムをスムーズに稼働させるための知識を得られるでしょう。
エラーハンドリングの難題
イベント駆動型アーキテクチャは、スケーラブルで疎結合なシステムを構築するのに最適です。しかし、エラーハンドリングに関しては、少し複雑になることがあります。モノリシックなアプリケーションではエラーの発生源を簡単に追跡できますが、分散システムではエラーがどこで、いつでも発生する可能性があり、その影響がシステム全体に波及するという独自の課題があります。
では、特にKafkaを使用するイベント駆動型システムでのエラーハンドリングがなぜ難しいのでしょうか?
- イベントの非同期性
- サービスの疎結合
- 連鎖的な失敗の可能性
- サービス境界を越えたエラーコンテキストの喪失
これらの課題に正面から取り組み、Kafkaトピック間でコンテキストを意識した失敗をプロのように伝播する方法を探りましょう。
コンテキストを意識したエラーイベントの設計
効果的なエラーハンドリングの第一歩は、十分なコンテキストを持つエラーイベントを設計することです。以下は、よく設計されたエラーイベントの例です:
{
"errorId": "e12345-67890-abcdef",
"timestamp": "2023-04-15T14:30:00Z",
"sourceService": "payment-processor",
"errorType": "PAYMENT_FAILURE",
"errorMessage": "クレジットカードが拒否されました",
"correlationId": "order-123456",
"stackTrace": "...",
"metadata": {
"orderId": "order-123456",
"userId": "user-789012",
"amount": 99.99
}
}
このエラーイベントには以下が含まれています:
- 追跡用のユニークなエラーID
- エラーが発生した時刻のタイムスタンプ
- エラーの発生元を特定するためのソースサービス
- 迅速な理解のためのエラータイプとメッセージ
- 関連するイベントをリンクするための相関ID
- 詳細なデバッグのためのスタックトレース
- コンテキストを提供するための関連メタデータ
エラー伝播の実装
エラーイベントの構造が整ったので、Kafkaトピック間でのエラー伝播の実装方法を見てみましょう。
1. 専用のエラートピックを作成する
まず、エラー用の専用Kafkaトピックを作成します。これにより、エラーハンドリングを集中化し、通常のイベントとは別にエラーを監視および処理しやすくなります。
kafka-topics.sh --create --topic error-events --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092
2. エラープロデューサーを実装する
サービス内で、例外が発生したときに専用のエラートピックにエラーイベントを送信するエラープロデューサーを実装します。以下はJavaとKafkaクライアントを使用した簡単な例です:
public class ErrorProducer {
private final KafkaProducer producer;
private static final String ERROR_TOPIC = "error-events";
public ErrorProducer(Properties kafkaProps) {
this.producer = new KafkaProducer<>(kafkaProps);
}
public void sendErrorEvent(ErrorEvent errorEvent) {
String errorJson = convertToJson(errorEvent);
ProducerRecord record = new ProducerRecord<>(ERROR_TOPIC, errorEvent.getErrorId(), errorJson);
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// エラーイベントの送信自体が失敗した場合の処理
System.err.println("エラーイベントの送信に失敗しました: " + exception.getMessage());
}
});
}
private String convertToJson(ErrorEvent errorEvent) {
// JSON変換ロジックをここに実装
}
}
3. エラーコンシューマーを実装する
エラートピックからエラーイベントを処理するエラーコンシューマーを作成します。これらのコンシューマーは、ログ記録、アラート、補償アクションのトリガーなど、さまざまなアクションを実行できます。
public class ErrorConsumer {
private final KafkaConsumer consumer;
private static final String ERROR_TOPIC = "error-events";
public ErrorConsumer(Properties kafkaProps) {
this.consumer = new KafkaConsumer<>(kafkaProps);
consumer.subscribe(Collections.singletonList(ERROR_TOPIC));
}
public void consumeErrors() {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
ErrorEvent errorEvent = parseErrorEvent(record.value());
processError(errorEvent);
}
}
}
private ErrorEvent parseErrorEvent(String json) {
// JSON解析ロジックをここに実装
}
private void processError(ErrorEvent errorEvent) {
// エラー処理ロジック(ログ記録、アラートなど)を実装
}
}
高度なエラーハンドリングパターン
基本を押さえたところで、イベント駆動型システムにおける高度なエラーハンドリングパターンを探ってみましょう。
1. サーキットブレーカーパターン
サービスが繰り返しエラーを起こしているときに連鎖的な失敗を防ぐためにサーキットブレーカーを実装します。このパターンは、システムが優雅に劣化し、回復するのを助けます。
public class CircuitBreaker {
private final long timeout;
private final int failureThreshold;
private int failureCount;
private long lastFailureTime;
private State state;
public CircuitBreaker(long timeout, int failureThreshold) {
this.timeout = timeout;
this.failureThreshold = failureThreshold;
this.state = State.CLOSED;
}
public boolean allowRequest() {
if (state == State.OPEN) {
if (System.currentTimeMillis() - lastFailureTime > timeout) {
state = State.HALF_OPEN;
return true;
}
return false;
}
return true;
}
public void recordSuccess() {
failureCount = 0;
state = State.CLOSED;
}
public void recordFailure() {
failureCount++;
lastFailureTime = System.currentTimeMillis();
if (failureCount >= failureThreshold) {
state = State.OPEN;
}
}
private enum State {
CLOSED, OPEN, HALF_OPEN
}
}
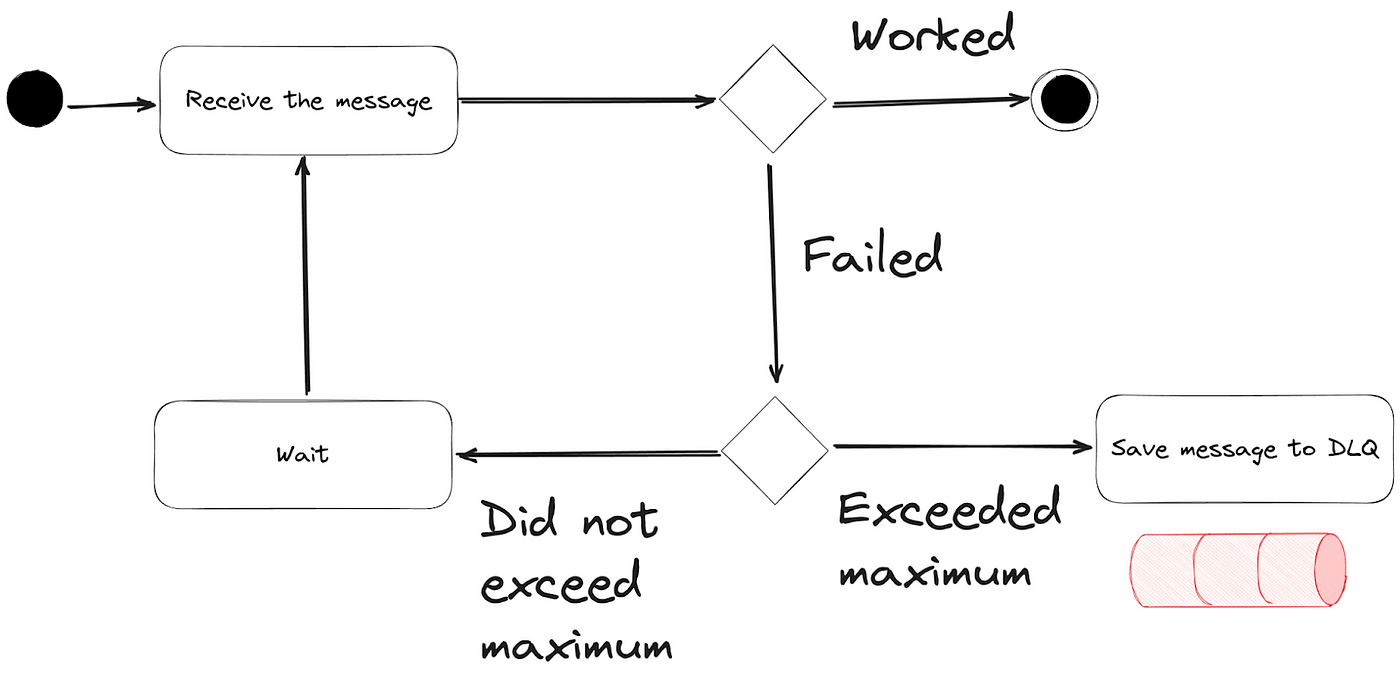
2. デッドレターキュー
処理に繰り返し失敗するメッセージのためにデッドレターキュー(DLQ)を実装します。これにより、問題のあるイベントを隔離し、後で分析および再処理することができます。
public class DeadLetterQueue {
private final KafkaProducer producer;
private static final String DLQ_TOPIC = "dead-letter-queue";
public DeadLetterQueue(Properties kafkaProps) {
this.producer = new KafkaProducer<>(kafkaProps);
}
public void sendToDLQ(String key, String value, String reason) {
DLQEvent dlqEvent = new DLQEvent(key, value, reason);
String dlqJson = convertToJson(dlqEvent);
ProducerRecord record = new ProducerRecord<>(DLQ_TOPIC, key, dlqJson);
producer.send(record);
}
private String convertToJson(DLQEvent dlqEvent) {
// JSON変換ロジックをここに実装
}
}
3. バックオフ付きリトライ
一時的なエラーに対して指数バックオフを伴うリトライメカニズムを実装します。これにより、システムは一時的な失敗から回復し、失敗しているコンポーネントを圧倒することなく再試行できます。
public class RetryWithBackoff {
private final int maxRetries;
private final long initialBackoff;
public RetryWithBackoff(int maxRetries, long initialBackoff) {
this.maxRetries = maxRetries;
this.initialBackoff = initialBackoff;
}
public void executeWithRetry(Runnable task) throws Exception {
int attempts = 0;
while (attempts < maxRetries) {
try {
task.run();
return;
} catch (Exception e) {
attempts++;
if (attempts >= maxRetries) {
throw e;
}
long backoff = initialBackoff * (long) Math.pow(2, attempts - 1);
Thread.sleep(backoff);
}
}
}
}
監視と可観測性
堅牢なエラーハンドリングを実装することは素晴らしいことですが、システムの健康状態を監視することも重要です。以下は監視と可観測性のためのいくつかのヒントです:
- JaegerやZipkinのような分散トレーシングツールを使用して、サービス間のリクエストを追跡する
- サービスにヘルスチェックエンドポイントを実装する
- エラー率やパターンに基づいてアラートを設定する
- ログ集約ツールを使用してログを集中化し、分析する
- エラートレンドやシステムの健康状態を視覚化するダッシュボードを作成する
結論:混乱を抑える
イベント駆動型システム、特にKafkaを使用する場合のエラーハンドリングは難しいことがあります。しかし、適切なアプローチを取ることで、潜在的な混乱をうまく制御されたシステムに変えることができます。コンテキストを意識したエラーイベントを設計し、適切なエラー伝播を実装し、高度なエラーハンドリングパターンを活用することで、堅牢でメンテナンスしやすいイベント駆動型システムを構築することができるでしょう。
効果的なエラーハンドリングは、単に例外をキャッチすることではなく、意味のあるコンテキストを提供し、迅速なデバッグを促進し、システムが失敗から優雅に回復できるようにすることです。これらのパターンを実装し、Kafkaトピックが常にエラーを意識していることを願っています!
「プログラミングの芸術は、複雑さを整理し、多様性をマスターし、その混乱を可能な限り効果的に回避する芸術である。」 - エドガー・W・ダイクストラ
これらの技術を身につけた今、イベント駆動型システムで最も複雑なエラーシナリオにも立ち向かう準備ができました。コーディングを楽しんでください、そしてエラーが常にコンテキストを意識していることを願っています!