なぜカーネルをバイパスするのか?
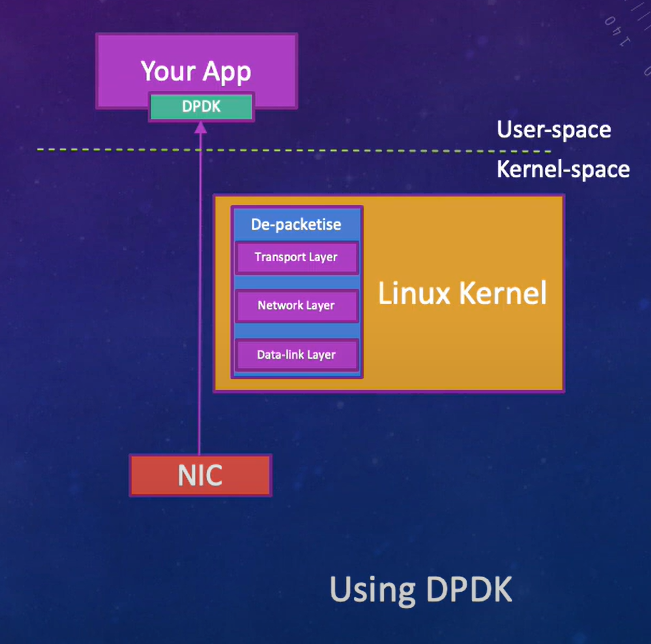
Linuxカーネルのネットワークスタックは、多様なプロトコルとユースケースを処理する技術の結晶です。しかし、一部の高性能アプリケーションにとっては、過剰な場合があります。必要なのはスイスアーミーナイフではなく、レーザービームのようなものです。
TCP/IPスタックをユーザースペースに移すことで、次のことが可能になります:
- カーネルとユーザースペース間のコンテキストスイッチを排除
- ポーリングを使用して割り込みを回避
- スタックを特定のニーズに合わせて調整
- メモリ割り当てとパケット処理を細かく制御
DPDKの登場:スピードの悪魔
Data Plane Development Kit (DPDK)は、この性能戦争における秘密兵器です。DPDKは、ユーザースペースでの高速パケット処理のためのライブラリとドライバのセットです。カーネルをバイパスし、ネットワークインターフェースカード(NIC)への直接アクセスを提供します。
使用するDPDKの主な機能:
- ポールモードドライバ(PMD):割り込みにさようなら!
- 巨大ページ:効率的なメモリ管理のために
- NUMA対応メモリ割り当て:データを必要なCPUの近くに保持
- ロックレスリングバッファ:ロックはもう古い
Rust:光速の安全性
なぜRustなのか?それは、プログラミング言語の中で最もクールな存在であるだけでなく、Rustは次のことを提供します:
- ゼロコスト抽象化:可読性を犠牲にしない性能
- ガベージコレクションなしのメモリ安全性:予期しない停止なし
- 恐れない並行性:すべてのコアを活用するために
- 成長するネットワーキングクレートのエコシステム:巨人の肩に立つ
設計図:スタックの構築
アプローチを管理可能な部分に分解しましょう:
1. DPDKのセットアップ
まず、DPDKをセットアップする必要があります。これには、DPDKのコンパイル、巨大ページの設定、NICをDPDK互換ドライバにバインドすることが含まれます。
# 依存関係をインストール
sudo apt-get install -y build-essential libnuma-dev
# DPDKをクローンしてコンパイル
git clone https://github.com/DPDK/dpdk.git
cd dpdk
meson build
ninja -C build
sudo ninja -C build install
2. RustとDPDK:天国でのマッチング
RustからDPDKとインターフェースするために、rust-dpdkクレートを使用します。これをCargo.tomlに追加します:
[dependencies]
rust-dpdk = "0.2"
3. RustでのDPDKの初期化
DPDKを起動しましょう:
use rust_dpdk::*;
fn main() {
// EAL(環境抽象化レイヤー)の初期化
let eal_args = vec![
"hello_dpdk".to_string(),
"-l".to_string(),
"0-3".to_string(),
"-n".to_string(),
"4".to_string(),
];
dpdk_init(eal_args).expect("DPDKの初期化に失敗しました");
// 残りのコード...
}
4. TCP/IPスタックの実装
ここからが楽しい部分です!基本的なTCP/IPスタックを実装します。以下は概要です:
- イーサネットフレームの処理
- IPパケットの処理
- TCPセグメントの管理
- 接続状態の追跡
簡略化されたTCPヘッダー解析関数を見てみましょう:
struct TcpHeader {
src_port: u16,
dst_port: u16,
seq_num: u32,
ack_num: u32,
// ... 他のフィールド
}
fn parse_tcp_header(packet: &[u8]) -> Result {
if packet.len() < 20 {
return Err(ParseError::PacketTooShort);
}
Ok(TcpHeader {
src_port: u16::from_be_bytes([packet[0], packet[1]]),
dst_port: u16::from_be_bytes([packet[2], packet[3]]),
seq_num: u32::from_be_bytes([packet[4], packet[5], packet[6], packet[7]]),
ack_num: u32::from_be_bytes([packet[8], packet[9], packet[10], packet[11]]),
// ... 他のフィールドを解析
})
}
5. ロックレスリングバッファの活用
DPDKのリングバッファは高性能を実現するための重要な要素です。これを使用して、処理パイプラインの異なる段階間でパケットを渡します:
use rust_dpdk::rte_ring::*;
// リングバッファを作成
let ring = rte_ring_create("packet_ring", 1024, SOCKET_ID_ANY, 0)
.expect("リングの作成に失敗しました");
// パケットをエンキュー
let mut packet: *mut rte_mbuf = /* ... */;
rte_ring_enqueue(ring, packet as *mut c_void);
// パケットをデキュー
let mut packet: *mut rte_mbuf = std::ptr::null_mut();
rte_ring_dequeue(ring, &mut packet as *mut *mut c_void);
6. ポールモードの魔法
割り込みを待つ代わりに、新しいパケットを継続的にポーリングします:
use rust_dpdk::rte_eth_rx_burst;
fn poll_for_packets(port_id: u16, queue_id: u16) {
let mut rx_pkts: [*mut rte_mbuf; 32] = [std::ptr::null_mut(); 32];
loop {
let nb_rx = unsafe {
rte_eth_rx_burst(port_id, queue_id, rx_pkts.as_mut_ptr(), rx_pkts.len() as u16)
};
for i in 0..nb_rx {
process_packet(rx_pkts[i as usize]);
}
}
}
パフォーマンスチューニング:スピードの必要性
10M+ PPSを達成するためには、スタックのあらゆる側面を最適化する必要があります:
- 複数のコアを使用し、適切な作業分配戦略を実装
- データ構造を整列させてキャッシュミスを最小化
- パケット処理をバッチ処理して関数呼び出しのオーバーヘッドを軽減
- 可能な限りゼロコピー操作を実装
- ホットパスを徹底的にプロファイルし最適化
潜在的な落とし穴:ここにドラゴンあり
ネットワークスタック全体を書き直す前に、次の潜在的な問題を考慮してください:
- 複雑さの増加:ユーザースペースネットワーキングのデバッグは困難です
- プロトコルサポートの制限:プロトコルをゼロから実装する必要があるかもしれません
- セキュリティの考慮:大きな力には大きな責任(および潜在的な脆弱性)が伴います
- 移植性:ソリューションが特定のハードウェアやDPDKバージョンに依存する可能性があります
ゴールライン:それは価値があったのか?
これだけの作業を経て、それが価値があったのか疑問に思うかもしれません。ソフトウェアエンジニアリングでは常に「それは場合による」という答えです。高頻度取引プラットフォーム、ネットワークアプライアンス、またはナノ秒が重要なシステムを構築している場合は、絶対に価値があります!以前は達成不可能だった新しいレベルのパフォーマンスを解放しました。
一方で、通常のWebアプリケーションを開発している場合、これは過剰かもしれません。早期の最適化はすべての悪の根源(または少なくともその木の重要な枝)であることを忘れないでください。
何を学んだか?
ユーザースペースネットワーキングの深淵への旅からの重要なポイントを振り返りましょう:
- カーネルをバイパスすることで、特定のユースケースで大幅な性能向上が得られる
- DPDKは高性能パケット処理のための強力なツールを提供
- Rustの安全性保証とゼロコスト抽象化は、システムプログラミングに最適
- 10M+ PPSを達成するには、スタックのあらゆるレベルでの慎重な最適化が必要
- 大きな力には大きな責任が伴う – ユーザースペースネットワーキングはすべてのアプリケーションに適しているわけではない
考えるための材料
締めくくりにあたり、考えるべき質問をいくつか提示します:
- eBPFのような技術の登場で、このアプローチはどのように変わるでしょうか?
- AI/MLを使用してパケット処理経路を動的に最適化できるでしょうか?
- このユーザースペースアプローチから恩恵を受ける可能性のある他のシステムプログラミングの分野は何でしょうか?
高性能ネットワーキングの世界では、唯一の限界はあなたの想像力です(そしておそらく光の速度ですが、それにも取り組んでいます)。さあ、ルーディクラススピードでパケットを処理しに行きましょう!
"インターネット?まだあるの?" - ホーマー・シンプソン
P.S. ここまで読んでくれたあなた、おめでとうございます!あなたは今や正式にネットワーキングオタクです。そのバッジを誇りに思い、あなたのパケットが常に目的地に到達することを願っています!