要約: 冪等性はあなたの新しい親友です
冪等性は、操作を繰り返してもシステムの状態が初回の適用を超えて変わらないことを保証します。これは、特にネットワークの問題、再試行、同時リクエストを扱う際に、分散システムの一貫性を維持するために重要です。以下の内容をカバーします:
- 冪等なREST API: 同じ注文が5つより1つの方が良い理由
- Kafkaコンシューマーの冪等性: メッセージが正確に一度だけ処理されることを保証
- 分散タスクキュー: ワーカーが協力して動作することを確実にする
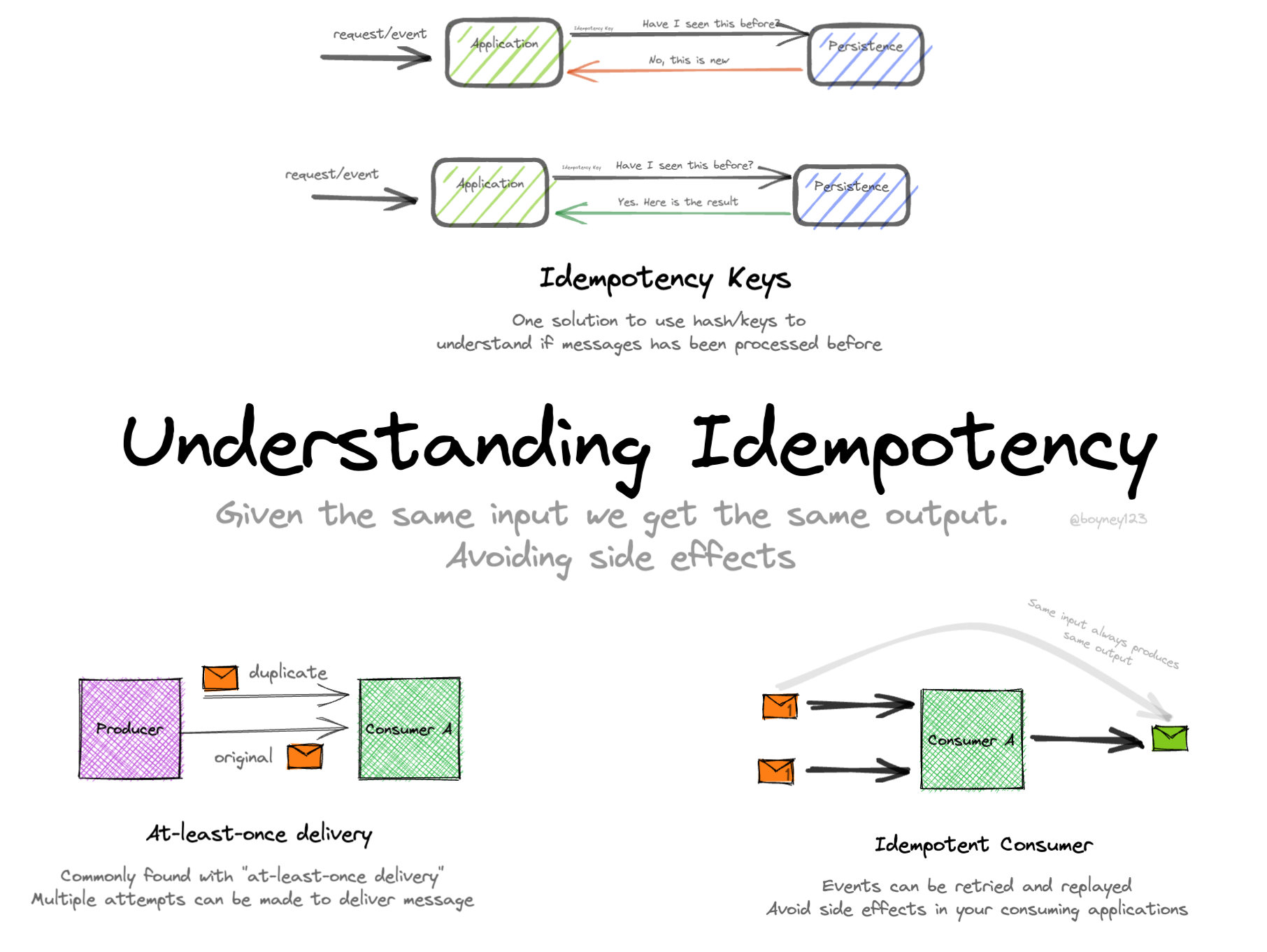
冪等なREST API: すべてを支配する1つの注文
まずはREST APIから始めましょう。これは現代のバックエンドシステムの基本です。ここでの冪等性の実装は、特に状態を変更する操作において重要です。
冪等性キーのパターン
効果的な手法の1つは、冪等性キーを使用することです。以下のように機能します:
- クライアントは各リクエストに対して一意の冪等性キーを生成します。
- サーバーはこのキーを最初の成功したリクエストの応答と共に保存します。
- 同じキーを持つ後続のリクエストに対して、サーバーは保存された応答を返します。
Flaskを使用したPythonの簡単な例を示します:
from flask import Flask, request, jsonify
import redis
app = Flask(__name__)
redis_client = redis.Redis(host='localhost', port=6379, db=0)
@app.route('/api/order', methods=['POST'])
def create_order():
idempotency_key = request.headers.get('Idempotency-Key')
if not idempotency_key:
return jsonify({"error": "Idempotency-Key header is required"}), 400
# このキーを以前に見たことがあるか確認
cached_response = redis_client.get(idempotency_key)
if cached_response:
return jsonify(eval(cached_response)), 200
# 注文を処理
order = process_order(request.json)
# 応答を保存
redis_client.set(idempotency_key, str(order), ex=3600) # 1時間後に期限切れ
return jsonify(order), 201
def process_order(order_data):
# 注文処理ロジック
return {"order_id": "12345", "status": "created"}
if __name__ == '__main__':
app.run(debug=True)
注意: キーの生成と期限切れ
冪等性キーのパターンは強力ですが、いくつかの課題があります:
- キーの生成: クライアントが本当に一意のキーを生成することを確認します。UUID4は良い選択ですが、潜在的な(非常に稀な)衝突を処理することを忘れないでください。
- キーの期限切れ: これらのキーを永遠に保持しないでください!システムのニーズに基づいて適切なTTLを設定します。
- ストレージのスケーラビリティ: システムが成長するにつれて、キーのストレージも増加します。インフラストラクチャでこれを計画します。
"大きな冪等性には大きな責任が伴います...そして多くのキー管理も必要です。"
Kafkaコンシューマーの冪等性: ストリームを制御する
ああ、Kafka!分散ストリーミングプラットフォームは、冪等性をどのように扱うかによって、あなたの親友にも悪夢にもなり得ます。
"正確に一度"のセマンティクス
Kafka 0.11.0は"正確に一度"のセマンティクスの概念を導入しました。これは冪等なコンシューマーにとって画期的です。以下のように活用します:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("enable.idempotence", true);
props.put("acks", "all");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", 5);
Producer producer = new KafkaProducer<>(props);
しかし、まだあります!本当に冪等性を達成するには、コンシューマーロジックも考慮する必要があります:
@KafkaListener(topics = "orders")
public void listen(ConsumerRecord record) {
String orderId = record.key();
String orderDetails = record.value();
// この注文を以前に処理したか確認
if (orderRepository.existsById(orderId)) {
log.info("Order {} already processed, skipping", orderId);
return;
}
// 注文を処理
Order order = processOrder(orderDetails);
orderRepository.save(order);
}
注意: 重複排除のジレンマ
Kafkaの正確に一度のセマンティクスは強力ですが、万能ではありません:
- 重複排除ウィンドウ: 処理済みメッセージをどのくらいの期間追跡しますか?短すぎると重複のリスクがあり、長すぎるとストレージが爆発します。
- 順序保証: 重複排除がメッセージの順序セマンティクスを壊さないようにします。
- ステートフル処理: 複雑なステートフル操作には、Kafka Streamsを使用して、より堅牢な冪等性を実現するための組み込みのステートストアを検討します。
分散タスクキュー: ワーカーが協力して動作する必要があるとき
CeleryやBullのような分散タスクキューは、作業をオフロードするのに最適ですが、冪等に扱わないと悪夢になります。ワーカーを制御するためのいくつかの戦略を見てみましょう。
"チェックしてから行動"パターン
このパターンは、タスクを実行する前に完了したかどうかを確認することを含みます。Celeryを使用した例を示します:
from celery import Celery
from myapp.models import Order
app = Celery('tasks', broker='redis://localhost:6379')
@app.task(bind=True, max_retries=3)
def process_order(self, order_id):
try:
order = Order.objects.get(id=order_id)
# 注文がすでに処理されているか確認
if order.status == 'processed':
return f"Order {order_id} already processed"
# 注文を処理
result = do_order_processing(order)
order.status = 'processed'
order.save()
return result
except Exception as exc:
self.retry(exc=exc, countdown=60) # 1分後に再試行
def do_order_processing(order):
# 実際の注文処理ロジック
pass
注意: レースコンディションと部分的な失敗
"チェックしてから行動"パターンには課題があります:
- レースコンディション: 高い同時実行シナリオでは、複数のワーカーが同時にチェックを通過する可能性があります。重要なセクションにはデータベースロックや分散ロック(例: Redisベース)を使用することを検討します。
- 部分的な失敗: タスクが途中で失敗した場合はどうしますか?タスクを完全に完了するか、完全にロールバック可能に設計します。
- 冪等性トークン: より複雑なシナリオには、以前に説明したREST APIパターンに似た冪等性トークンシステムの実装を検討します。
哲学的な視点: なぜこれほどの騒ぎが必要なのか?
「なぜこんなに手間をかけるのか?ただYOLOでやってみて、うまくいくことを祈ればいいのでは?」と思うかもしれません。しかし、分散システムの世界では、希望は戦略ではありません。冪等性は重要です。なぜなら:
- システム全体のデータの一貫性を保証します。
- ネットワークの問題や再試行に対してシステムをより強靭にします。
- エラーハンドリングとデバッグを簡素化します。
- 分散アーキテクチャのスケーリングとメンテナンスを容易にします。
"分散システムでは、冪等性は単なる付加価値ではなく、失敗を優雅に処理するシステムと、'ネットワーク分割'と言うより早く混乱に陥るシステムの違いです。"
まとめ: 冪等性ツールキット
見てきたように、分散バックエンドシステムでの冪等性の実装は簡単ではありませんが、堅牢でスケーラブルなアプリケーションを構築するためには絶対に重要です。以下は冪等性ツールキットです:
- REST APIの場合: 冪等性キーと慎重なリクエスト処理を使用します。
- Kafkaコンシューマーの場合: "正確に一度"のセマンティクスを活用し、スマートな重複排除を実装します。
- 分散タスクキューの場合: "チェックしてから行動"パターンを採用し、レースコンディションに注意します。
冪等性は単なる機能ではなく、マインドセットです。システムの設計段階から考え始めると、ネットワークの問題、サービスの再起動、そして恐ろしい午前3時の本番問題に直面しても、サービスがスムーズに動作し続けることに感謝するでしょう。
さあ、分散システムを冪等にしましょう!将来の自分(と運用チーム)が感謝するでしょう。
さらなる学習
コーディングを楽しんで、システムが常に一貫していることを願っています!