ブルームフィルタはデータの世界の用心棒のようなものです。データセットに何かが「おそらく」存在するか「確実に」存在しないかを、実際にドアを開けることなく素早く教えてくれます。この確率的データ構造は、不要な検索やネットワーク呼び出しを大幅に削減し、システムをより高速かつ効率的にします。
舞台裏の魔法
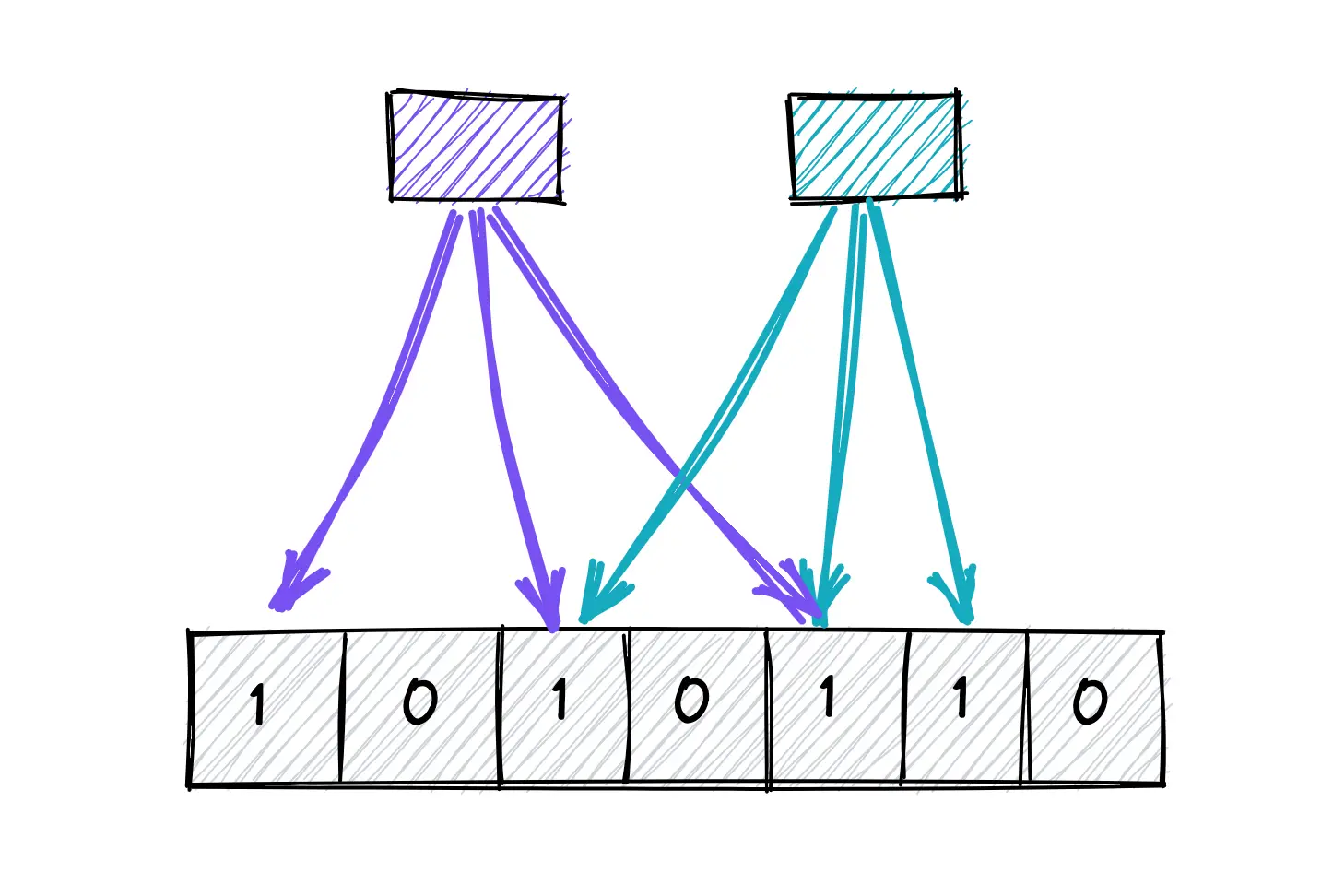
ブルームフィルタの基本はビットの配列です。要素を追加するとき、それは複数回ハッシュ化され、対応するビットが1に設定されます。要素が存在するかどうかを確認するには、再度ハッシュ化して、すべての対応するビットが設定されているかを確認します。シンプルですが強力です。
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = [0] * size
def add(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
self.bit_array[index] = 1
def check(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
if self.bit_array[index] == 0:
return False
return True
実世界での応用: ブルームフィルタが輝く場所
ブルームフィルタが役立つ実際のシナリオを見てみましょう:
1. キャッシングシステム: ゲートキーパー
大規模なキャッシングシステムを運用していると想像してください。高価なバックエンドストレージにアクセスする前に、ブルームフィルタを使用してキーがキャッシュに存在する「可能性がある」かどうかを確認できます。
def get_item(key):
if not bloom_filter.check(key):
return None # 確実にキャッシュにない
# キャッシュにあるかもしれないので確認
return actual_cache.get(key)
このシンプルなチェックにより、キャッシュミスや不要なバックエンドクエリを大幅に削減できます。
2. 検索最適化: クイックエリミネーター
分散検索システムでは、ブルームフィルタがプレフィルタとして機能し、シャード全体での不要な検索を排除できます。
def search_shards(query):
results = []
for shard in shards:
if shard.bloom_filter.check(query):
results.extend(shard.search(query))
return results
クエリを含まないことが確実なシャードを素早く排除することで、ネットワークトラフィックを削減し、検索時間を改善できます。
3. 重複検出: 効率的なデデュプリケーター
ウェブをクロールしたり、大量のデータストリームを処理したりする際には、重複を迅速に検出することが重要です。
def process_item(item):
if not bloom_filter.check(item):
bloom_filter.add(item)
process_new_item(item)
else:
# 以前に見た可能性があるので追加の確認を行う
pass
このアプローチは、処理済みアイテムの完全なリストを保持するのに比べてメモリ使用量を大幅に削減できます。
細部: ブルームフィルタの調整
良いツールと同様に、ブルームフィルタも適切な調整が必要です。以下は重要な考慮事項です:
- サイズが重要: フィルタが大きいほど、偽陽性率は低くなりますが、メモリ使用量が増えます。
- ハッシュ関数: ハッシュ関数が多いほど偽陽性が減りますが、計算時間が増えます。
- 予想アイテム数: データサイズを知ることでフィルタのパラメータを最適化できます。
ブルームフィルタのサイズを決定するための簡単な公式はこちらです:
import math
def optimal_bloom_filter_size(item_count, false_positive_rate):
m = -(item_count * math.log(false_positive_rate)) / (math.log(2)**2)
k = (m / item_count) * math.log(2)
return int(m), int(k)
# 使用例
items = 1000000
fp_rate = 0.01
size, hash_count = optimal_bloom_filter_size(items, fp_rate)
print(f"最適なサイズ: {size} ビット")
print(f"最適なハッシュ数: {hash_count}")
注意点と考慮事項
ブルームフィルタを使いすぎる前に、以下の点に注意してください:
- 偽陽性が存在する: ブルームフィルタは、アイテムが存在する可能性があると示すことがありますが、実際には存在しないことがあります。エラーハンドリングでこれを考慮してください。
- 削除不可: 標準のブルームフィルタはアイテムの削除をサポートしていません。削除機能が必要な場合は、カウントブルームフィルタを検討してください。
- 万能ではない: 強力ですが、ブルームフィルタはすべてのシナリオに適しているわけではありません。使用ケースを慎重に評価してください。
"大いなる力には大いなる責任が伴う。ブルームフィルタを賢く使えば、バックエンドを正しく扱ってくれるでしょう。" - ソフトウェアアーキテクトのアンクル・ベン
ブルームフィルタをスタックに統合する
ブルームフィルタを試してみる準備はできましたか?以下は始めるための人気のあるライブラリです:
大局的な視点: なぜ気にするのか?
大局的に見ると、ブルームフィルタは単なる巧妙なトリック以上のものです。システム設計におけるより広範な原則を表しています: 時には、少しの不確実性が大きなパフォーマンス向上につながることがあります。偽陽性の小さな確率を受け入れることで、より高速でスケーラブルで効率的なシステムを作成できます。
考えるための材料
ブルームフィルタをアーキテクチャに実装する際には、次の質問を考慮してください:
- ブルームフィルタの確率的な性質がシステム設計の他の部分にどのように影響を与えるか?
- 完全な精度を速度と引き換えることが有益な他のシナリオは何か?
- ブルームフィルタの使用がシステムのSLAやエラーバジェットとどのように一致するか?
まとめ: ブルームはバラから離れた
ブルームフィルタは町の新しいホットなものではないかもしれませんが、時間の試練に耐えた、戦闘で鍛えられたツールであり、バックエンドツールキットにふさわしい場所を持っています。キャッシングから検索最適化まで、これらの確率的な力持ちは、分散システムに求められるパフォーマンス向上を提供できます。
次にデータの洪水やクエリの泥沼に直面したときは、解決策がブルームにあることを思い出してください。
さあ、フィルタをかけに行きましょう、素晴らしいバックエンドの名手たちよ!