優雅な劣化とは、システムが100%でなくても機能を維持することです。サーキットブレーカー、レート制限、優先順位付けなどの戦略を探り、バックエンドがどんな嵐にも耐えられるようにします。準備はいいですか?少し揺れるかもしれませんが、教育的な旅になりますよ!
なぜ優雅な劣化が重要なのか?
理想の世界では、システムは24時間365日完璧に動作するでしょう。しかし、現実の世界では、マーフィーの法則が常に潜んでいます。優雅な劣化は、マーフィーに対して「いい試みだが、こちらには対策がある」と言う方法です。
その重要性は以下の通りです:
- 重要な機能を維持し、問題が発生してもシステムを動かし続ける
- システム全体をダウンさせる連鎖的な障害を防ぐ
- 高負荷時のユーザー体験を向上させる
- 全面的な危機を避けつつ問題を修正する余裕を持つ
優雅な劣化のための戦略
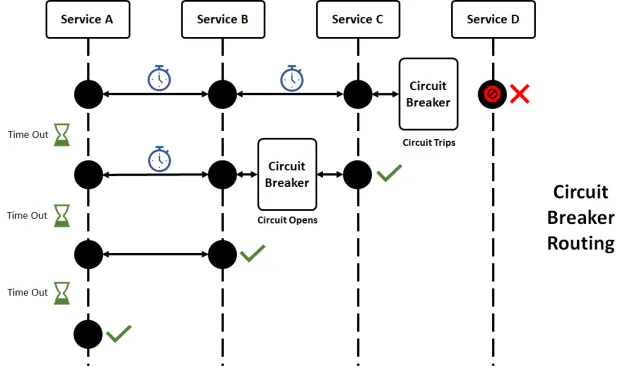
1. サーキットブレーカー: システムのヒューズボックス
子供の頃、クリスマスライトをたくさんつなげてヒューズを飛ばしたことを覚えていますか?ソフトウェアのサーキットブレーカーは同様に、システムを過負荷から守ります。
Hystrixライブラリを使った簡単な実装例です:
public class ExampleCommand extends HystrixCommand {
private final String name;
public ExampleCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// これはAPIコールやデータベースクエリかもしれません
return "Hello " + name + "!";
}
@Override
protected String getFallback() {
return "Hello Guest!";
}
}
この例では、run()メソッドが失敗したり時間がかかりすぎたりすると、サーキットブレーカーが作動し、getFallback()が呼び出されます。コードのバックアップ発電機のようなものです!
2. レート制限: APIにマナーを教える
レート制限はクラブのバウンサーのようなものです。一度に多くのリクエストが殺到しないようにします。Spring BootとBucket4jを使った実装例です:
@RestController
public class ApiController {
private final Bucket bucket;
public ApiController() {
Bandwidth limit = Bandwidth.classic(20, Refill.greedy(20, Duration.ofMinutes(1)));
this.bucket = Bucket.builder()
.addLimit(limit)
.build();
}
@GetMapping("/api/resource")
public ResponseEntity getResource() {
if (bucket.tryConsume(1)) {
return ResponseEntity.ok("Here's your resource!");
}
return ResponseEntity.status(429).body("Too many requests, please try again later.");
}
}
この設定では、1分間に20リクエストを許可します。それ以上は、後で再試行するように丁寧にお願いされます。APIが順番待ちを学んだようなものです!
3. 優先順位付け: すべてのリクエストが同等ではない
状況が厳しくなったとき、何を優先するかを知る必要があります。これはERのトリアージのようなもので、重要な操作を最初に、猫のGIFは後で(猫好きの方、ごめんなさい)。
リクエストの優先キューを実装することを考えてみてください:
public class PriorityRequestQueue {
private PriorityQueue queue;
public PriorityRequestQueue() {
this.queue = new PriorityQueue<>((r1, r2) -> r2.getPriority() - r1.getPriority());
}
public void addRequest(Request request) {
queue.offer(request);
}
public Request processNextRequest() {
return queue.poll();
}
}
これにより、リソースが限られているときに高優先度のリクエスト(支払いなどの重要なユーザーアクション)が最初に処理されることが保証されます。
優雅に失敗する技術
いくつかの戦略をカバーしたので、優雅に失敗する技術について話しましょう。完全な崩壊を避けるだけでなく、逆境に直面しても品位を保つことです。以下のヒントがあります:
- 明確なコミュニケーション: サービスを劣化させるときは、ユーザーに透明性を持たせましょう。「高い需要により、一部の機能が一時的に利用できない場合があります」といった簡単なメッセージが大いに役立ちます。
- 段階的な劣化: 100から0に一気に行かないでください。非重要な機能を最初に無効にし、可能な限りコア機能を維持します。
- インテリジェントな再試行: すでにストレスを受けているサービスを叩かないように、指数バックオフを実装します。
- キャッシング戦略: ピーク時にバックエンドサービスの負荷を減らすために、キャッシングを賢く使用します。
モニタリング: 早期警告システム
優雅な劣化戦略を実装するのは素晴らしいことですが、いつそれを発動するかを知るにはどうすればいいでしょうか?モニタリングがその答えです。システムの早期警告システムです。
PrometheusやGrafanaのようなツールを使って、重要なメトリクスを監視することを考えてみてください:
- 応答時間
- エラーレート
- CPUとメモリの使用量
- キューの長さ
問題が発生したときだけでなく、少し怪しいときにもアラートを設定します。システムの天気予報のようなもので、嵐が来る前に知りたいものです。
劣化戦略のテスト
コードをテストせずにデプロイすることはないですよね?(ですよね?!)劣化戦略も同様です。カオスエンジニアリングに入ります。意図的に壊す技術です。
Chaos Monkeyのようなツールを使って、制御された環境で障害や高負荷シナリオをシミュレートすることができます。システムのための火災訓練のようなものです。少し神経を使うかもしれませんが、実際の火災のときにスプリンクラーが動かないことを知るよりは良いでしょう。
実例: Netflixのアプローチ
ストリーミングの巨人Netflixがどのように優雅な劣化を扱っているかを見てみましょう。彼らは「優先順位によるフォールバック」という技術を使用しています。彼らのアプローチを簡単に説明します:
- ユーザーのためにパーソナライズされたおすすめを取得しようとします。
- それが失敗した場合、その地域の人気タイトルにフォールバックします。
- 地域データが利用できない場合、全体の人気タイトルを表示します。
- 最後の手段として、事前に定義された静的なタイトルリストを表示します。
これにより、理想的なパーソナライズされた体験でなくても、ユーザーは常に何かを見ることができます。機能を劣化させながらも価値を提供する素晴らしい例です。
結論: カオスを受け入れる
優雅な劣化の設計は、単に障害を処理することではなく、分散システムの混沌とした性質を受け入れることです。問題が発生することを受け入れ、それに備えることです。「おっと、私たちのミス!」と言うのと「私たちはこれをコントロールしています」と言うのとの違いです。
覚えておいてください:
- 連鎖的な障害を防ぐためにサーキットブレーカーを実装する
- 高負荷シナリオを管理するためにレート制限を使用する
- リソースが不足しているときに重要な操作を優先する
- 劣化状態のときにユーザーと明確にコミュニケーションを取る
- モニタリング、テスト、そして劣化戦略を継続的に改善する
これらの戦略に従うことで、単なるシステムを構築するのではなく、デジタル世界が投げかけるどんなカオスにも立ち向かう準備ができた、戦闘テスト済みの強靭な戦士を構築することになります。さあ、優雅に劣化しましょう!
「システムの真のテストは、すべてがうまくいっているときではなく、すべてがうまくいっていないときにどのように振る舞うかです。」 - 匿名のDevOps哲学者
あなたのシステムでの優雅な劣化についての戦いの話はありますか?コメントで共有してください!結局のところ、ある開発者の悪夢は他の開発者の学習の機会です。コーディングを楽しんで、システムが常に優雅に劣化することを願っています!