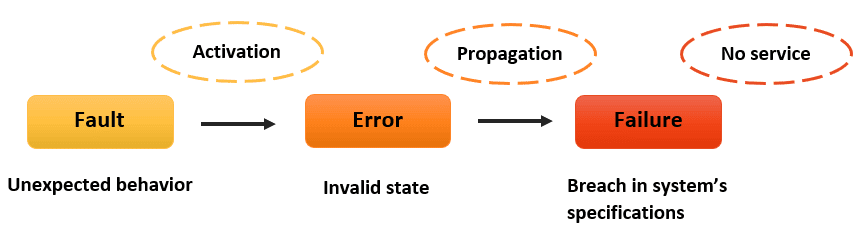
このディープダイブでは、エラー伝播の高度なメカニズムに取り組みます。最も厄介なエラーを処理できるカスタムのフォールトトレランスレイヤーを構築し、分散システムを壊れやすいスマートフォンの世界でノキア3310のように頑丈に保つ方法を探ります。
エラー伝播の難題
解決策に飛び込む前に、問題を理解するための時間を取りましょう。分散システムでは、エラーはおしゃべりな隣人のようなもので、すぐに広がり、放置すると大騒ぎを引き起こす可能性があります。
次のシナリオを考えてみましょう:
# サービスA
def process_order(order_id):
try:
user = get_user_info(order_id)
items = get_order_items(order_id)
payment = process_payment(user, items)
shipping = arrange_shipping(user, items)
return {"status": "success", "order_id": order_id}
except Exception as e:
return {"status": "error", "message": str(e)}
# サービスB
def get_user_info(order_id):
# データベースエラーをシミュレート
raise DatabaseConnectionError("ユーザーデータベースに接続できません")
この単純な例では、サービスBのエラーがサービスAに伝播し、連鎖的な失敗を引き起こす可能性があります。しかし、これらのエラーをインターセプトし、分析し、賢く対応できたらどうでしょうか?そこでカスタムのフォールトトレランスレイヤーが登場します。
フォールトトレランスレイヤーの構築
フォールトトレランスレイヤーは、いくつかの重要なコンポーネントで構成されます:
- エラー分類システム
- 伝播ルールエンジン
- サーキットブレーカーの実装
- 指数バックオフを用いたリトライメカニズム
- フォールバック戦略
これらを一つずつ見ていきましょう。
1. エラー分類システム
最初のステップは、エラーをその重大度と潜在的な影響に基づいて分類することです。カスタムのエラーヒエラルキーを作成します:
class BaseError(Exception):
def __init__(self, message, severity):
self.message = message
self.severity = severity
class TransientError(BaseError):
def __init__(self, message):
super().__init__(message, severity="LOW")
class PartialOutageError(BaseError):
def __init__(self, message):
super().__init__(message, severity="MEDIUM")
class CriticalError(BaseError):
def __init__(self, message):
super().__init__(message, severity="HIGH")
この分類により、エラーの重大度に応じて異なる方法でエラーを処理できます。
2. 伝播ルールエンジン
次に、エラーがシステム内でどのように伝播するかを決定するルールエンジンを作成します:
class PropagationRulesEngine:
def __init__(self):
self.rules = {
TransientError: self.handle_transient,
PartialOutageError: self.handle_partial_outage,
CriticalError: self.handle_critical
}
def handle_error(self, error):
handler = self.rules.get(type(error), self.default_handler)
return handler(error)
def handle_transient(self, error):
# リトライロジックを実装
pass
def handle_partial_outage(self, error):
# フォールバック戦略を実装
pass
def handle_critical(self, error):
# サーキットブレーカーを実装
pass
def default_handler(self, error):
# ログを記録し伝播
logging.error(f"未処理のエラー: {error}")
raise error
このエンジンにより、異なるエラータイプに対して特定の動作を定義できます。
3. サーキットブレーカーの実装
連鎖的な失敗を防ぐために、サーキットブレーカーパターンを実装します:
import time
class CircuitBreaker:
def __init__(self, failure_threshold, reset_timeout):
self.failure_count = 0
self.failure_threshold = failure_threshold
self.reset_timeout = reset_timeout
self.last_failure_time = None
self.state = "CLOSED"
def execute(self, func, *args, **kwargs):
if self.state == "OPEN":
if time.time() - self.last_failure_time > self.reset_timeout:
self.state = "HALF-OPEN"
else:
raise CircuitBreakerOpenError("サーキットがオープンしています")
try:
result = func(*args, **kwargs)
if self.state == "HALF-OPEN":
self.state = "CLOSED"
self.failure_count = 0
return result
except Exception as e:
self.failure_count += 1
if self.failure_count >= self.failure_threshold:
self.state = "OPEN"
self.last_failure_time = time.time()
raise e
このサーキットブレーカーは、一定数の失敗が発生したときに自動的に「トリップ」し、問題のあるサービスへのさらなる呼び出しを防ぎます。
4. 指数バックオフを用いたリトライメカニズム
一時的なエラーに対しては、指数バックオフを用いたリトライメカニズムが非常に有用です:
import random
import time
def retry_with_backoff(retries=3, backoff_in_seconds=1):
def decorator(func):
def wrapper(*args, **kwargs):
x = 0
while True:
try:
return func(*args, **kwargs)
except TransientError as e:
if x == retries:
raise e
sleep = (backoff_in_seconds * 2 ** x +
random.uniform(0, 1))
time.sleep(sleep)
x += 1
return wrapper
return decorator
@retry_with_backoff(retries=5, backoff_in_seconds=1)
def unreliable_function():
# 不安定な関数をシミュレート
if random.random() < 0.7:
raise TransientError("一時的な失敗")
return "成功!"
このデコレーターは、試行間の遅延を増やしながら自動的に関数をリトライします。
5. フォールバック戦略
最後に、すべてが失敗したときのためのフォールバック戦略を実装しましょう:
class FallbackStrategy:
def __init__(self):
self.strategies = {
"get_user_info": self.fallback_user_info,
"process_payment": self.fallback_payment,
"arrange_shipping": self.fallback_shipping
}
def execute_fallback(self, function_name, *args, **kwargs):
fallback = self.strategies.get(function_name)
if fallback:
return fallback(*args, **kwargs)
raise NoFallbackError(f"{function_name}のフォールバック戦略がありません")
def fallback_user_info(self, order_id):
# キャッシュまたはデフォルトのユーザー情報を返す
return {"user_id": "default", "name": "John Doe"}
def fallback_payment(self, user, items):
# 支払いを保留としてマークし、続行
return {"status": "pending", "message": "支払いは後で処理されます"}
def fallback_shipping(self, user, items):
# デフォルトの配送方法を使用
return {"method": "standard", "estimated_delivery": "5-7営業日"}
これらのフォールバック戦略は、通常の操作が失敗したときの安全策を提供します。
すべてをまとめる
すべてのコンポーネントが揃ったので、分散システムでどのように機能するかを見てみましょう:
class FaultToleranceLayer:
def __init__(self):
self.rules_engine = PropagationRulesEngine()
self.circuit_breaker = CircuitBreaker(failure_threshold=5, reset_timeout=60)
self.fallback_strategy = FallbackStrategy()
def execute(self, func, *args, **kwargs):
try:
return self.circuit_breaker.execute(func, *args, **kwargs)
except Exception as e:
try:
return self.rules_engine.handle_error(e)
except Exception:
return self.fallback_strategy.execute_fallback(func.__name__, *args, **kwargs)
# フォールトトレランスレイヤーの使用
fault_tolerance = FaultToleranceLayer()
@retry_with_backoff(retries=3, backoff_in_seconds=1)
def get_user_info(order_id):
# 実際の実装
pass
def process_order(order_id):
user = fault_tolerance.execute(get_user_info, order_id)
# 注文処理の残りのロジック
pass
このセットアップにより、システムはさまざまなエラーシナリオを優雅に処理し、連鎖的な失敗を防ぎ、全体的な信頼性を向上させます。
成果:より強靭なシステム
このカスタムフォールトトレランスレイヤーを実装することで、分散システムの強靭性が大幅に向上しました。得られたものは次のとおりです:
- エラータイプと重大度に基づくインテリジェントなエラー処理
- 一時的な失敗に対する自動リトライ
- サーキットブレーカーによる連鎖的な失敗の防止
- フォールバック戦略による優雅な劣化
- エラーパターンとシステム動作の可視性の向上
フォールトトレラントな分散システムの構築は継続的なプロセスです。システムの動作を継続的に監視し、エラー処理戦略を洗練し、新たな失敗モードに適応してください。
考えるべきこと
独自のフォールトトレランスレイヤーを実装する際には、次の質問を考慮してください:
- 分類システムにうまく収まらないエラーをどのように処理しますか?
- フォールトトレランスメカニズムの効果を評価するためにどのような指標を使用しますか?
- 強靭性への欲求とシステムの応答性の必要性をどのようにバランスさせますか?
- このフォールトトレランスレイヤーを活用してシステムの可観測性をどのように向上させますか?
分散システムの世界では、エラーは避けられないだけでなく、システムを強化する機会でもあります。エラー処理を楽しんでください!